Analysis of ARM hardware runs |
In this note we relax our model and compare its output with hardware. Thereby we intend to study hardware experiments that invalidate our model in greater detail.
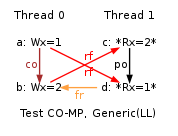
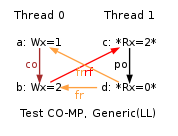
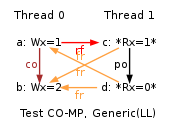
ARM acknowledges “Read-afer-Read Hazards” in a “Programmer Advice Notice”, referenced as ARM 761319. The notice applies to Cortex A9- MPCore and can explain many of the model invalidations we report in the companion page Comparing model and hardware. For instance it explains the following behaviours of test CO-MP.
To cancel the impact of this read-after-read hazard phenomenon, we relax
the ARM model.
The sc per location condition reads as “acyclic po-loc | fr | rf | co”,
or equivalently as:
let complus = (fr | rf | co)+ irreflexive po-loc;complus
That is, successive accesses to the same memory cell never contradict communication relations. Read-after-read hazards permit two successive reads to contradict the communication relations. We account for this relaxation by replacing the sc per location check by the following, more relaxed, check:
let complus = (fr | rf | co)+ irreflexive (WW(po-loc) | RW(po-loc) | WR(po-loc));complus
We then compare the resulting Relaxed-LL model with hardware. The new model is more permissive than the old one, since we have made the sc per location check more permissive. However this does not suffices: as illustrated by the comparison table, there are still many observation that invalidate the relaxed model.
As integrating read-after-read hazards by relaxing the sc per location condition des not suffice to allow all executions that invalidate our model, we now relax the model even more. Test MP+dmb+fri-rfi-ctrlisb is worth examining further, as its invalid execution1 cannot be obtained by relaxing sc per location.
| Model | Tegra2 | APQ8060 | A5X | A6X | Exynos5250 | Tegra3 | Exynos4412 | Exynos5410 | APQ8064 | |
| MP+dmb+fri-rfi-ctrlisb | Forbid | No, 0/44G | Ok, 153k/10G | No, 0/9.0G | No, 0/14G | No, 0/8.3G | No, 0/62G | No, 0/34G | No, 0/6.3G | No, 0/4.7G |
| Allow unseen | Allow unseen | Allow unseen | Allow unseen | Allow unseen | Allow unseen | Allow unseen | Allow unseen |
Executions for behaviour:
"1:R0=1 ; 1:R2=2 ; 1:R3=0 ; y=2"
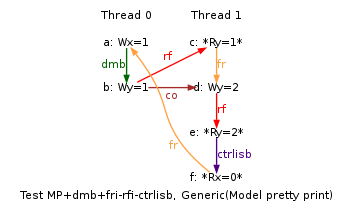
Indeed the loads of y by Thread 1 read correct values, namely first 1 (written by Thread 0) and then 2 (written by Thread 1 itself). Those loads do not contradict the coherence order for y, which orders the store of 1 before the store of 2, as demonstrated by y final value of 2. However, the execution is forbidden by our base model, while being observed on Qualcomm APQ8060 and claimed to be legal by our ARM contact. Also notice that we have observed more such invalid behaviours mostly on Qualcomm APQ8060 and APQ8064, here are a few LB+data+fri-rfi-addr, LB+data+fri-rfi-ctrl, LB+data+fri-rfi-data, MP+dmb+fri-rfi-ctrlisb, S+dmb+fri-rfi-addr, S+dmb+fri-rfi-ctrl, S+dmb+fri-rfi-data, LB+data+data-wsi-rfi-addr, LB+data+data-wsi-rfi-ctrl, LB+data+data-wsi-rfi-ctrl+BIS and MP+dmb+fri-rfi-ctrlisb+BIS. All those have in common a “fri; rfi” sequence (for instance MP+dmb+fri-rfi-ctrlisb) or “coi; rfi” (for instance LB+data+data-wsi-rfi-ctrl). The observation MP+dmb+fri-rfi-ctrlisb+BIS is also worth noticing, as the observation took place on Nvdia Tegra3. Those are forbidden by our base model, as such “fri; rfi” and “coi; rfi” induce some ordering constraints that finally participate to the definition of the preserved program order (ppo).
More precisely, we track the issue down to the definition of the preserved-program-order (ppo) relation which commands in-order commits for accesses to the same memory cell — See the cc0 relation below:
(*******) (* ppo *) (*******) (* Initial value *) let ci0 = ctrlisync | detour let ii0 = dd | rfi | rdw let cc0 = dd | po-loc | ctrl | addrpo let ic0 = 0 ...
We thus relax the model further by a more permissive definition of ppo that does not enforce in-order commits for accesses to the same memory cell:
... let cc0 = dd | ctrl | addrpo (* po-loc deleted *) ...
This new alteration results in a new (even more relaxed) model Relaxed, which we now compare with hardware.
Unfortunately as illustrated by the 35 invalid tests (totalling 1160 executions) of this table, the relaxed model is still invalid.
There are still quite a lot of invalid tests (exactly 35). To shed some light on those we resort to automatic classification. From the resulting tables, we can explain the new invalid behaviours, that is the behaviours that are forbidden by the relaxed model armllh.cat while being observed on hardware.
During our analysis we found some invalid executions that look rather serious. They noticeably include a new violation of sc per location, and some violations of the MP+fence+ppo idiom, such as MP+dmb+ctrlisb, which are paradigms of fence and dependency usage to restore order.
However we observe:
Finally, it is quite hard to draw conclusions on models from experimenting on hardware that we cannot totally trust. Hence, although we cannot claim our model to be definitive, we nevertheless claim that our proposed ARM model is a decent approximation of current ARM hardware behaviour, saved from some hardware bugs on the one hand, and corner cases on the other hand.
In section Relaxing preserved program order we adopted a rather radical mean to allow the invalid behaviour of MP+dmb+fri-rfi-ctrlisb:
Executions for behaviour:
"1:R0=1 ; 1:R2=2 ; 1:R3=0 ; y=2"
Namely, so as to allow the read e to commit before the read c, we have allowed all accessses to the same location to commit out of order. More specifically, we have removed po-loc from the cc0 component of the preserved program order ppo, writing:
... let cc0 = dd | ctrl | addrpo (* po-loc deleted *) ...
A less radical approach consists in removing selected component from the ppo relation:
As a result, we can attempt a less relaxed definition of cc0 that will still force write-to-write, read-to-write pairs to commit in-order.
... let cc0 = dd | ctrl | addrpo | WW(po-loc) | RW(po-loc) ...
The resulting model lessrelaxed.cat is less relaxed than the armllh.cat model, since the only difference between the two models is a less permissive preserved program order (ppo). Some comparison tables list the tests that lessrelaxed.cat forbids and armllh.cat allows.
However, considering our test base, both models have exactly the same invalid behaviours as suggested by the counts of invalid tests and executions: 35 tests totalling 1160 invalid executions on the one hand; and 35 tests totalling 1160 invalid executions on the other hand.
More precisely, one can compare the classification of invalid behaviours for both models and check that they are identical: classifications for armllh.cat and lessrelaxed.cat.
This document was translated from LATEX by HEVEA.