


Part III |
The tool herd is a memory model simulator. Users may write simple, single events, axiomatic models of their own and run litmus tests on top of their model. The herd distribution already includes some models.
The authors of herd are Jade Alglave and Luc Maranget.
The simulator herd accepts models written in text files. For instance here is sc.cat, the definition of the sequentially consistent (SC) model:
SC (* Atomic *) empty atom & (fre;coe) as atom (* Sequential consistency *) acyclic po | fr | rf | co as sc
The model above illustrate two features of model definitions:
let construct.
Here, a new relation com is the union “|” of
the three pre-defined communication relations.
po|com”
(i.e. the union of program order po and of communication
relations) is required to be acyclic.
We postpone the discussion of the show instruction, see
Sec. 13.
One can then run some litmus test, for instance SB (for Store Buffering, see also Sec. 1.1), on top of the SC model:
% herd -model ./sc.cat SB.litmus Test SB Allowed States 3 0:EAX=0; 1:EAX=1; 0:EAX=1; 1:EAX=0; 0:EAX=1; 1:EAX=1; No Witnesses Positive: 0 Negative: 3 Condition exists (0:EAX=0 /\ 1:EAX=0) Observation SB Never 0 3 Hash=7dbd6b8e6dd4abc2ef3d48b0376fb2e3
The output of herd mainly consists in
the list of final states that are allowed by the simulated model.
Additional output relates to the test condition.
One sees that the test condition does not validate on top of SC,
as “No” appears just after the list of final states
and as there is no “Positive” witness.
Namely, the condition “exists (0:EAX=0 /\ 1:EAX=0)”
reflects a non-SC behaviour, see Sec. 5.2.
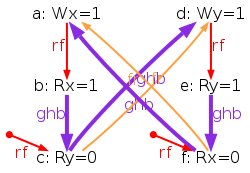
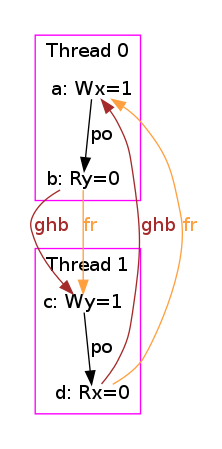
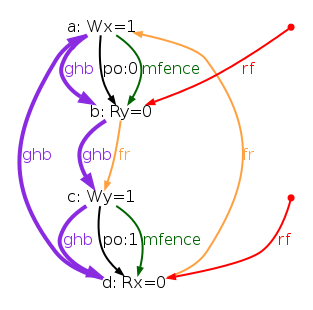
The simulator herd works by generating all executions of a given test. By “execution” we mean a choice of events, program order po, read-from rf, and coherence orders co4. In the case of the SB example, we get the following four executions:
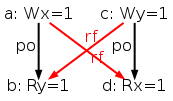
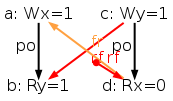
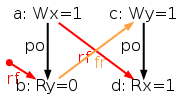
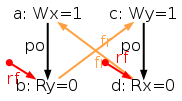
Indeed, there is no choice for the program order po, as there are no conditional jumps in this example; and no choice for the coherence orders co either, as there is only one store per location, which must be co-after the initial stores (not pictured for clarity). Then, there are two read events from locations x and y respectively, which take their values either from the initial stores or from the stores in program. As a result, there are four possible executions. The model sc.cat gets executed on each of the four (candidate) executions. The three first executions are accepted and the last one is rejected, as it presents a cycle in po ∪ fr. The following diagram pictures the ghb relation. The cycle is obvious:
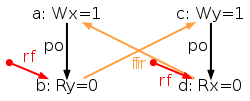
However, the non-SC execution shows up on x86 machines, whose memory model is TSO. As TSO relaxes the write-to-read order, we attempt to write a TSO model tso-00.cat, by simply removing write-to-read pairs from the acyclicity check:
"A first attempt for TSO" (* Communication relations that order events*) let com-tso = rf | co | fr (* Program order that orders events *) let po-tso = WW(po) | RM(po) (* TSP global-happens-before *) let ghb = po-tso | com-tso acyclic ghb show ghb
This model illustrates another feature of model definitions: filters
such as WW and RM restrict their argument by selecting
some sort of events. As W stands for write events, R for
read events and M for all memory events, the effect of
let po-tso = WW(po)|RM(po) is to define po-tso as the program
order minus write-to-read pairs.
We run SB on top of the tentative TSO model:
% herd -model tso-00.cat SB.litmus Test SB Allowed States 4 0:EAX=0; 1:EAX=0; 0:EAX=0; 1:EAX=1; 0:EAX=1; 1:EAX=0; 0:EAX=1; 1:EAX=1; Ok Witnesses Positive: 1 Negative: 3 ...
The non-SC behaviour is now accepted, as write-to-read po-pairs do not participate to the acyclicity check any more. In effect, this allows the last execution above, as ghb (i.e. po-tso ∪ com-tso) is acyclic.
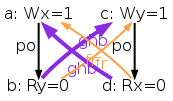
However, our model tso-00.cat is flawed: it is still to strict, forbidding some behaviours that the TSO model should accept. Consider the test SB+rfi-pos, which is test STFW-PPC for X86 from Sec. 1.3 with a normalised name (see Sec. 10.1). This test targets the following execution:
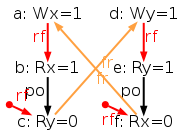
Namely the test condition
exists (0:EAX=1 /\ 0:EBX=0 /\ 1:EAX=1 /\ 1:EBX=0)
specifies that Thread 0 writes 1 into location x,
reads the value 1 from the location x (possibly by store forwarding) and
then reads the value 0 from the location y;
while Thread 1 writes 1 into y,
reads 1 from y and then reads 0 from x.
Hence, this test derives from the previour SB
by adding loads in the middle, those loads
being satisfied from local stores.
As can be seen by running the test on top of the tso-00.cat
model, the target execution is forbidden:
% herd -model tso-00.cat SB+rfi-pos.litmus Test SB+rfi-pos Allowed States 15 0:EAX=0; 0:EBX=0; 1:EAX=0; 1:EBX=0; ... 0:EAX=1; 0:EBX=1; 1:EAX=1; 1:EBX=1; No Witnesses Positive: 0 Negative: 15 ..
However, running the test with litmus demonstrates that the behaviour is observed on some X86 machine:
% arch x86_64 % litmus -mach x86 SB+rfi-pos.litmus ... Test SB+rfi-pos Allowed Histogram (4 states) 11589 *>0:EAX=1; 0:EBX=0; 1:EAX=1; 1:EBX=0; 3993715:>0:EAX=1; 0:EBX=1; 1:EAX=1; 1:EBX=0; 3994308:>0:EAX=1; 0:EBX=0; 1:EAX=1; 1:EBX=1; 388 :>0:EAX=1; 0:EBX=1; 1:EAX=1; 1:EBX=1; Ok Witnesses Positive: 11589, Negative: 7988411 Condition exists (0:EAX=1 /\ 0:EBX=0 /\ 1:EAX=1 /\ 1:EBX=0) is validated ...
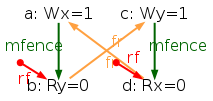
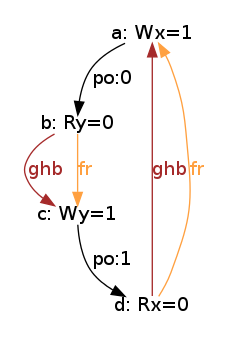
As a conclusion, our tentative TSO model is too strong. The following diagram pictures its ghb relation:
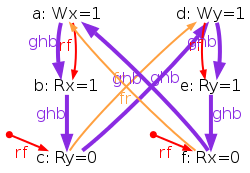
One easily sees that ghb is cyclic, wheras it should not. Namely, the internal read-from relation rfi does not create global order in the TSO model. Hence, rfi is not included in ghb. We rephrase our tentative TSO model, resulting into the new model tso-01.cat:
"A second attempt for TSO" (* Communication relations that order events*) let com-tso = rfe | co | fr (* Program order that orders events *) let po-tso = WW(po) | RM(po) (* TSP global-happens-before *) let ghb = po-tso | com-tso acyclic ghb show ghb
As can be observed above rfi (internal read-from) is no longer included in ghb. However, rfe (external read-from) still is.
As intended, this new tentative TSO model allows the behaviour of test SB+rfi-pos:
% herd -model tso-01.cat SB+rfi-pos.litmus Test SB+rfi-pos Allowed States 16 ... 0:EAX=1; 0:EBX=1; 1:EAX=1; 1:EBX=0; ... Ok Witnesses Positive: 1 Negative: 15 ...
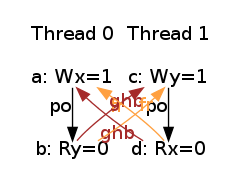
And indeed, the global-happens-before relation is no-longer cyclic:
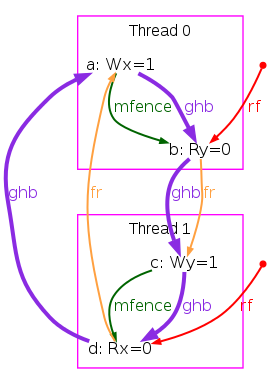
We are not done yet, as our model is too weak in two aspects. First, it has no semantics for fences. As a result the test SB+mfences is allowed, whereas it should be forbidden, as this is the very purpose of the fence mfence.
One easily solves this issue by adding the mfence relation
to the definition of po-tso:
let po-tso = WW(po) | RM(po) | mfence
But the resulting model is still too weak, as it allows some behaviours that any model must reject for the sake of single thread correctness. The following test CoRWR illustrates the issue:
X86 CoRWR
{ }
P0 ;
MOV EAX,[x] ;
MOV [x],$1 ;
MOV EBX,[x] ;
exists (0:EAX=1 /\ 0:EBX=0)
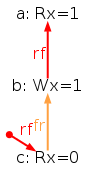
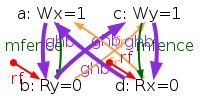
The TSO check “acyclic po-tso|com-tso” does not suffice to reject
two absurd behaviours pictured in the execution diagram above:
(1) the read a is allowed to
read from the po-after write b, as rfi is not included
in com-tso; and (2)
the read c is allowed to read the initial value of location x
although
this (unpictured) write is co-before the write b,
as WR(po) is not in po-tso.
For any model, we rule out those very
untimely behaviours by the so-called
uniproc
check that states that executions projected on events that access one variable
only are SC.
In practice, having defined po-loc as po restricted to
events that touch the same address, we further require the acyclicity
of the relation po-loc|fr|rf|co.
In the TSO case, the uniproc check can be
somehow simplified by considering only
the cycles in po-loc|fr|rf|co that
are not already rejected by the main check of the model.
This amounts to design specific checks for the two relations that are
not global in TSO: rfi and WR(po).
Doing so, we finally produce a correct model for TSO tso-02.cat:
"A third attempt for TSO" (* Uniproc check specialized for TSO *) irreflexive RW(po-loc);rfi as uniprocRW irreflexive WR(po-loc);fri as uniprocWR (* Communication relations that order events*) let com-tso = rfe | co | fr (* Program order that orders events *) let po-tso = WW(po) | RM(po) | mfence (* TSP global-happens-before *) let ghb = po-tso | com-tso show mfence ghb acyclic ghb as tso
This last model illustrates other features of herd:
herd may also performs irreflexivity checks with the keyword
“irreflexive”; and
the checks can be given names by suffixing them with
“as name”.
This last feature will be used in Sec. 13.2
The simulator herd can be instructed to produce pictures of executions. Those pictures are instrumental in understanding and debugging models. It is important to understand that herd does not produce pictures by default. To get pictures one must instruct herd to produce pictures of some executions with the -show option. This option accepts specific keywords, its default being “none”, instructing herd not to produce any picture.
A frequentlty used keyword is “prop” that means “show the executions
that validate the proposition in the final condition”.
Namely, the final condition in litmus test is a quantified
boolean proposition as for instance “exists (0:EAX=0 /\ 1:EAX=0)” at the end of test SB.
But this is not enough, users also have to specify what to do with the picture: save it in file in the DOT format of the graphviz graph visualization software, or display the image,5 or both. One instructs herd to save images with the -o dirname option, where dirname is the name of a directory, which must exists. Then, when processing the file name.litmus, herd will create a file name.dot into the directory dirname. For displaying images, one uses the -gv option.
As an example, so as to display the image of the non-SC behaviour of SB, one should invoke herd as:
% herd -model tso-02.cat -show prop -gv SB.litmus
As a result, users should see a window popping and displaying this image:
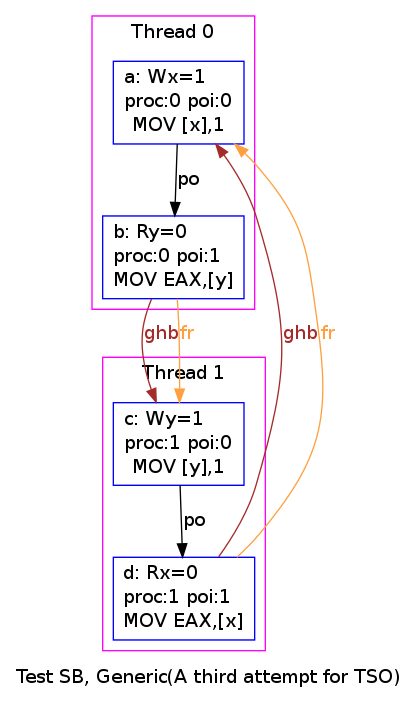
Notice that we got the PNG version of this image as follows:
% herd -model tso-02.cat -show prop -o /tmp SB.litmus % dot -Tpng /tmp/SB.dot -o SB+CLUSTER.png
That is, we applied the dot tool from the graphviz package, using the appropriate option to produce a PNG image.
One may observe that there are ghb arrows in the diagram.
This results from the show ghb instruction
at the end of the model file tso-02.cat.
The image above much differs from the one in Sec. 12.2 that describes the same execution and that is reproduced in Fig. 3
Figure 3: The non-SC behaviour of SB is allowed by TSO
In effect, herd can produce three styles of pictures, dot clustered pictures, dot free pictures, and neato pictures with explicit placement of the events of one thread as a colum. The style is commanded by the -graph option that accepts three possible arguments: cluster (default), free and columns. The following pictures show the effect of graph styles on the SB example:
| -graph cluster | -graph free | -graph columns |
 |  | 
|
Notice that we used another option -squished true that much reduces the information displayed in nodes. Also notice that the first two pictures are formatted by dot, while the rightmost picture is formatted by neato.
One may also observe that the “-graph columns” picture does not look exactly like Fig. 3. For instance the ghb arrows are thicker in the figure. There are many parameters to control neato (and dot), many of which are accessible to herd users by the means of appropriate options. We do not intend to describe them all. However, users can reproduce the style of the diagram of this manual using yet another feature of herd: configuration files that contains settings for herd options and that are loaded with the -conf name option. In this manual we mostly used the doc.cfg configuration file. As this file is present in herd distribution, users
can use the diagram style of this manual:
% herd -conf doc.cfg ...
Images are produced or displayed once the model has been executed. As a consequence, forbidden executions won’t appear by default. Consider for instance the test SB+mfences, where the mfence instruction is used to forbid SB non-SC execution. Runing herd as
% herd -model tso-02.cat -conf doc.cfg -show prop -gv SB+mfences.litmus
will produce no picture, as the TSO model forbids the target execution of SB+mfences.
To get a picture, we can run SB+mfences on top of the mininal model, a pre-defined model that allows all executions:
% herd -model minimal -conf doc.cfg -show prop -gv SB+mfences.litmus
And we get the picture:
It is worth mentioning again that although the minimal model allows all executions, the final condition selects the displayed picture, as we have specified the -show prop option.
The picture above shows mfence arrows, as all
fence relations are displayed by the minimal model.
However, it does not show the ghb relation, as the minimal
model knows nothing of it.
To display ghb we could write another model file that would be just as
tso-02.cat, with checks erased.
The simulator herd provides a simpler technique:
one can instruct herd to ignore
either all checks (-through invalid), or a selection of checks
(-skipcheck name1… namen).
Thus, either of the following two commands
% herd -through invalid -model tso-02.cat -conf doc.cfg -show prop -gv SB+mfences.litmus % herd -skipcheck tso -model tso-02.cat -conf doc.cfg -show prop -gv SB+mfences.litmus
will produce the picture we wish:
Notice that mfence and ghb are displayed because
of the instruction “show mfence ghb” (fence relation are not shown
by default);
while -skipcheck tso works because the tso-02.cat model
names its main check with “as tso”.
The image above is barely readable.
For such graphs with many relations, the cluster and free modes
are worth a try. The commands:
% herd -skipcheck tso -model tso-02.cat -conf doc.cfg -show prop -graph cluster -gv SB+mfences.litmus % herd -skipcheck tso -model tso-02.cat -conf doc.cfg -show prop -graph free -gv SB+mfences.litmus
will produce the images:
 | 
|
Namely, command line options are scanned left-to-right,
so that most of the settings of doc.cfg are kept6
(for instance thick ghb arrows), while the graph mode is overriden.
We describe our langage for defining models. The syntax of the language is given in BNF-like notation. Terminal symbols are set in typewriter font (like this). Non-terminal symbols are set in italic font (like that). An unformatted vertical bar …∣ … denotes alternative. Square brackets […] denote optional components. Curly brackets {…} denotes zero, one or several repetitions of the enclosed components.
Model source files may contain comments of the OCaml type
((*…*), can be nested), or line comments starting with
“#” and running until end of line.
|
Identifiers are rather standard: they are a sequence of letters, digits, “_” (the underscore character), “.” (the dot character) and “-” (the minus character), starting with a letter. Using the minus character inside identifiers may look a bit surprising. We did so as to allow identifiers such as po-loc.
At startup, pre-defined identifiers are bound to relations between memory events. Those relations describe a candidate execution. Executing the model means allowing or forbiding that candidate execution.
A first pre-defined identifier is id, the identity. Other pre-defined identifiers are the program order po and its refinements:
| identifier | name | description | ||
| po | program order | instruction order lifted to events | ||
| po-loc | po restricted to the same address | events are in po and touch the same address | ||
| addr | address dependency | the address of the second event depends on the value loaded by the first (read) event | ||
| data | data dependency | the value stored by the second (write) event depends on the value loaded by the first (read) event | ||
| ctrl | control dependency | the second event is in a branch controled by the value loaded by the commfirst (read) event | ||
| ctrlisync/ctrlisb | control dependency + isync/isb | the branch additionally contains a isync/isb barrier before the second event | ||
Other pre-defined relations denote the presence of a specific fence (or barrier) in-between two events, those are mfence, sfence, lfence (X86); sync, lwsync, lwsync, isync (Power); and dsb, dmb, dsb.st, dmb.st, isb (ARM).
Finally, pre-defined identifiers are bound the communication relations:
| identifier | name | description | ||
| rf | read-from | links a write w to a read r taking its value from w | ||
| co | coherence | total order over writes to the same address | ||
| fr | from-read | links a read r to a write w′ co-after the write w from which r takes its value | ||
| rfi, fri, coi | internal communications | communication between events of the same thread | ||
| rfe, fre, coe | external communications | communication between events of different threads | ||
Expressions are evaluated by herd, yielding a relation over memory events as a value. A relation can be seen as a set of pairs of memory events.
|
Simple expressions are the empty relation (keyword 0) and identifiers id. Identifiers are bound to values, either before the execution (see pre-defined identifiers in Sec. 14.1), or by the model itself.
The transitive and reflexive-transitive closure of an expression are performed by the postfix operators + and *. The postfix operator ^-1 performs relation inversion. The construct expr? (option) evaluates to the union of expr value and of the identity relation.
Infix operators are | (union), ; (sequence), & (intersection) and \ (set difference). The precedence of operators is as follows: postfix operators bind tighter than infix operators. Infix operators from higher precedence to lower precedence are: &, \, ; and |. All infix operators are right-associative, except set difference which is left-associative.
For the record, given two relations r1 and r2, the sequence r1; r2 is defined as { (x,y) ∣ ∃ z, (x,z) ∈ r1 ∧ (z,y) ∈ r2}.
Selectors are filters that operate on relations. The value of selector( expr) is some subrelation of the value of expr. Which subrelation depends upon selector.
Most selectors are two-letters keywords with the first letter operating on the first component of pairs and the second letter operating on the second component of pairs. More precisely, we define the semantics of selector letters as predicates over memory events: M always yield true, R yields true on read events, W yields true on write events, A yields true on atomic events (produced by X86 locked instructions, or ARM/Power load reserve and store conditional instructions), and P yields true on ordinary (plain) events. Then, we define:
| XY(r) = { (x,y) ∈ r ∣ X(x) ∧ Y(y)} |
For instance, the expression RW(po) yields the read-to-write pairs
in program order.
Three additional selectors ext, int, and noid performs specific operations. The first selects pairs of events in different threads (“external”), the second selects pairs of events in the same thread (“internal”), and the third selects pairs of events that are different (“not identical”).
Functions calls are written id( expr1 , … , exprn). That is, functions have an arity (n above, which can be zero) and arguments are given as a comma separated list of expressions. Our language have call-by-value semantics. That is, the effective parameters expr1 , … , exprn are evaluated before being bound to formal parameters.
Functions are first class values, as reflected by the anonymous function construct fun ( params ) -> expr. Function arity is defined by the length of its formal parameter list params, which can be empty. Notice that functions have the usual static scoping semantics: variables that appear free in function bodies (expr above) are bound to the value of such free variable at function creation time.
The local binding construct let [ rec ] bindings in expr binds the names defined by bindings for evaluating the expression expr.
Both non-recursive and recursive bindings are allowed. The function binding id ( params ) = expr is syntactic sugar for id = fun ( params ) -> expr. It is allowed in non-recursive bindings only as there is little point in defining recursive function in our setting.
In the following we only consider value bindings id = expr. The construct
evaluates expr1,…, exprn, and binds the names id1,…, idn to the resulting values.
The construct
computes the least fixpoint of the equations id1 = expr1,…, idn = exprn. It then binds the names id1,…, idn to the resulting values. The least fixpoint computation applies only to relations, using inclusion for ordering. Notice that let rec id = fun ( params ) -> expr in… is legal syntax. Such a definition will yield a runtime error.
The expression (expr) has the same value as expr. Notice that a parenthesised expression can also be written as begin expr end.
Instruction are executed for their effect. There are three kind of effects: adding new bindings, checking a condition, and specifying relations that are shown in pictures.
|
The let and let rec constructs bind value names for the rest of model execution. See the subsection on bindings in Section 14.2 for additional information on the syntax and semantics of bindings.
Recursive definitions computes fixpoints of relations. For instance, the following fragment computes the transitive closure of all communication relations:
let com = rf | co | fr let rec complus = com | (complus ; complus)
Notice that the instruction let complus = (rf|co|fr)+ is equivalent.
There are no recursive functions, as those would not be very useful in our limited language. Nevertheless, one may for instance write a generic transitive closure function by using a local recursive binding:
let tr(r) = let rec t = r | (t;t) in t let complus = tr(rf|co|fr)
Again notice that the instruction
let complus = (rf|co|fr)+ is equivalent.
The construct
evaluates expr and applies check. If the check succeeds, that is if the relation is acyclic, irreflexive or empty; depending on check being acyclic, irreflexive or empty, execution goes on. Otherwise, execution stops.
The performance of a check can optionally be named by appending as id after it. The feature permits not to perform some checks at user’s will, thanks to the -skipcheck id command line option.
Procedures are similar to functions except that they have no results: the body of a procedure is a list of instructions and the procedure will be called for the effect of executing those instructions. Intended usage of procedures is to define checks that are executed later. However, the body of a procedure may consist in any kind of instructions.
For instance, one may define the following uniproc procedure with
no arguments:
procedure uniproc() = let com = fr | rf | co in acyclic com | po
Then one can perform the acyclicity check (see previous section) by executing the instruction:
call uniproc()
As a result the execution will stop if the acyclicity check fails, or continue otherwise.
Procedures are lexically scoped as functions are. Additionally, the bindings performed during the execution of a procedure call are discarded when the procedure returns, all other effects performed are retained.
take (non-empty, comma separated) lists of identifiers as arguments. The show construct adds the present values of identifiers for being shown in pictures. The unshow construct removes the identifiers from shown relations.
The more sophisticated construct
evaluates expr to a relation, which will be shown in pictures with label id. Hence show id can be viewed as a shorthand for show id as id
The construct include "filename" is interpreted as
the inclusion of the model contained in the file whose name is given as
an argument to the include instruction.
In practice the list of intructions defined by the included model file
are executed.
The string argument is delimited by double quotes “"”,
which, of course, are not part of the filename.
Notice that:
|
A model is a a list of instruction preceded by a small comment,
which can be either a name that follows herd conventions for identifiers,
or a string enclosed in double quotes “"”,
and a list of options.
Models operate on candidate executions (see Sec. 14.1), instructions are executed in sequence, until one instruction stops, or until the end of the instruction list. In that latter case, the model accepts the execution. The accepted execution is then passed over to the rest of herd engine, in order to collect final states of locations and to display pictures.
Model options control some experimental features of herd. More precisely, by default, herd includes a complete coherence order relation in every candidate execution, and does not represent initial writes by plain memory write events. Said otherwise, by default, model files have options withco and whithoutinit.
The generation of all possible coherence orders by herd engine is a source of inefficiency that can be alleviated by having the model itself compute the sub-relation of co that is really useful. Such models must have option withoutco, so as to prevent herd engine from generating all coherence orders. Instead, herd will represent initial writes as plain write events (i.e. option withoutco implies withinit) identify last writes in coherence oders, and pass the model a reduced co relation, named co0, that will, for any memory location x, relate the initial write to x to all writes to x, and all writes to x to the final write to x. It is then the model responsability to compute the remainder of co from the program read events. The model uniproccat.cat from the distribution gives an example of such an advanced model.
The option withinit can also be given alone so as to instruct herd engine to represent initial writes as plain write events. In such a situation, herd will compute complete coherence orders co that include those explicit initial writes as minimal elements. Observe that the representation of initial writes as events can be also controlled from the command-line (see option -initwrites) and that command line settings override model options.
The command herd handles its arguments like litmus. That is, herd interprets its argument as file names. Those files are either a single litmus test when having extension .litmus, or a list of file names when prefixed by @.
There are many command line options. We describe the more useful ones:
The main purpose of herd is to run tests on top of memory models. For a given test, herd performs a three stage process:
We now describe options that control those three stages.
In fact, herd accepts potentially infinitely many models, as models can given in text files in an adhoc language described in Sec. 14. The herd distribution includes several such models: herd.cat, minimal.cat, uniproc.cat and x86tso.cat are text file versions of the homonymous internal models, but may produce pictures that show different relations. Model files are searched according to the same rules as configuration files.
exists p, ~exists p, or forall p.
The semantics of recognised tags is as follows:
exists and forall, and false
for ~exists.
exists and ~exists,
and false for forall.
Those options intentionally omit some of the final states that herd would normally generate.
exists p is validated, and as soon as a condition ~exists p or
forall p is invalidated. Default is false.<int> pictures have been collected. Default is to
collect all (specified, see option -show) pictures.
These options control the content of DOT images.
We first describe options that act at the general level.
\myth{n}. Assembler instructions are locations in nodes
are argument to an \asm command. It user responsability to define
those commands in their LATEX documents that include the pictures.
Possible definitions are \newcommand{\myth}[1]{Thread~#1}
and \newcommand{\asm}[1]{\texttt{#1}}.
Default is false.
A few options control picture legends.
exists,
kind Forbid being ~exists,
and kind Require being forall.
Default is false.
A few options control what is shown in nodes and on their sizes, i.e. on how events are pictured.
Then we list options that offer some control on which edges are shown.
We recall that the main controls over the shown and unshown edges are
the show and unshow directives in model definitions —
see Sec. 14.3.
However, some edges can be controled only with options (or configuration
files) and the -unshow option proves convenient.
show directive in model definition and any -doshow command
line option.
Other options offer some control over some of the attributes defined in Graphviz software documentation. Notice that the controlled attributes are omitted from DOT files when no setting is present. For instance in the absence of a -spline <tag> option, herd will generate no definition for the splines attribute thus resorting to DOT tools defaults. Most of the following options accept the none argument that restores their default behaviour.
Those options are the same as the ones of litmus — see Sec. 4.
exists,
kind Forbid being ~exists
and kind Require being forall.
The syntax of configuration files is minimal: lines “key arg” are interpreted as setting the value of parameter key to arg. Each parameter has a corresponding option, usually -key, except for the single letter option -v whose parameter is verbose.
As command line option are processed left-to-right, settings from a configuration file (option -conf) can be overridden by a later command line option. Configuration files will be used mostly for controling pictures. Some configuration files are are present in the distribution. As an example, here is the configuration file apoil.cfg, which can be used to display images in free mode.
#Main graph mode graph free #Show memory events only showevents memory #Minimal information in nodes squished true #Do not show a legend at all showlegend false
The configuration above is commented with line comments that starts
with “#”.
The above configuration file comes handy to eye-proof model output,
even for relatively complex tests, such as IRIW+lwsyncs
and IRIW+syncs:
% herd -conf apoil.cfg -show prop -gv IRIW+lwsyncs.litmus % herd -through invalid -conf apoil.cfg -show prop -gv IRIW+syncs.litmus
We run the two tests on top of the default model that computes, amongst others, a prop relation. The model rejects executions with a cyclic prop. One can then see that the relation prop is acyclic for IRIW+lwsyncs and cyclic for IRIW+syncs:
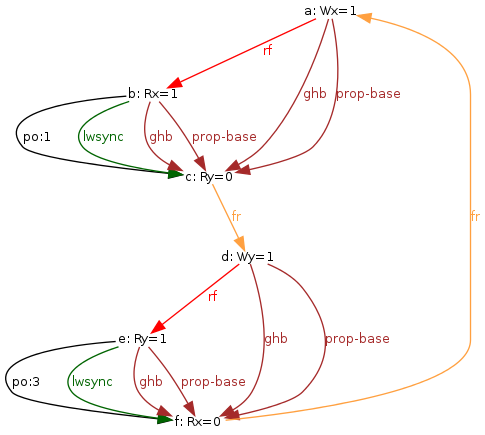
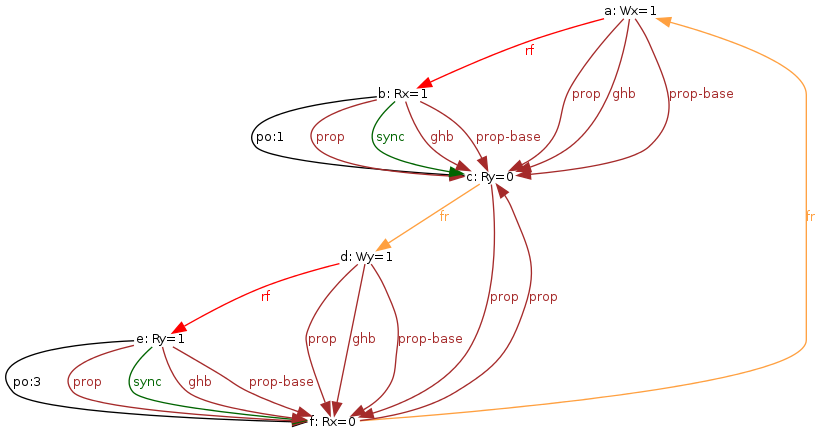
Notice that we used the option -through invalid in the case of IRIW+syncs as we would otherwise have no image.
Configuration and model files are searched first in the current directory; then in any directory specified by setting the shell environment variable HERDDIR; and then in herd installation directory, which is defined while compiling herd.
This section describes several extensions to herd that have been implemented by Tyler Sorensen and John Wickerson in collaboration with the original authors. In due course, the contents of this section will probably be merged into the previous sections to form a cohesive manual.
Note. It is necessary to provide a litmus test when invoking herd in this way, even though the litmus test will not be examined. This is due to a minor technical problem.
This is an amendment to Section 14.2.
The syntax of expressions with respect to function application is currently described as:
|
In fact, the syntax is more general: multiple arguments may be given, in a currying fashion. For instance, one may write such expressions as f (a,b) (c,d,e). The syntax should therefore be updated as follows:
|
This is an appendix to Section 14.2.
Models can now define expressions over sets, and also bind identifiers to sets. The syntax of expressions thus becomes:
|
We write {} for the empty set (in contrast to 0 for the empty relation), _ for the universal set of all events in the event structure, ~ for the complement of a relation, and ! for the complement of a set. If s and t represent sets, then s * t builds their cross product. We also provide [ s ], which denotes the relation that links each element of s to itself.
This is an appendix to Section 14.3.
A test-instruction is used to enforce a contract between the programming language and the programmer. There are two types: provided conditions and undefined-unless conditions. The latter are indicated with the undefined_unless keyword. A provided condition is an obligation on the programming language; that is, the programmer can assume that every execution of their program will satisfy every provided condition. An undefined-unless condition is an obligation on the programmer; that is, the compiler-writer can assume that every execution of the program will satisfy every undefined-unless condition. In other words, if a program has an execution that violates an undefined-unless condition, then its behaviour is completely undefined.
The syntax for instructions thus becomes:
|
This is an appendix to Section 14.1.
Here are some more pre-defined relations.
| identifier | name | description | ||
| unv | universal relation | relates every event in the structure to every other event | ||
| int-s | internal at given scope | (applicable only to scoped memory models) relates events that are in the same part of the execution hierarchy | ||
| ext-s | external at given scope | (applicable only to scoped memory models) relates events that are in different parts of the execution hierarchy | ||
Here, s ranges over the following values:
| value of s | description (in OpenCL terminology) |
| wi, thread | work-item |
| sg, warp | sub-group |
| wg, block, cta | work-group |
| kernel | kernel |
| dev | device |
For example, int-cta relates all events that are in the same work-group, while ext-wi relates all events that are in different work-items (threads).
We provide the following additional fence relations: membar.cta, membar.gl, membar.sys (PTX). C++ and OpenCL fences do not appear in this list because those fences are modelled as events rather than relations. By modelling these fences as events, we are better able to attach parameters to them, such as the memory-order (C++ and OpenCL) and the memory-scope (OpenCL).
In C++ models, the following relations are pre-defined.
| identifier | name | description | ||
| asw | additional synchronises-with | links every initial write to every event that is not an initial write | ||
| lo | lock order | a total order on all mutex operations (similar to co, but for mutexes instead of writes) | ||
Here are some pre-defined sets, available in all models.
| identifier | name | description | ||
| _ | universal set | the set of all events in the structure | ||
| R | read events | set of all reads from memory | ||
| W | write events | set of all writes to memory | ||
| M | memory events | set of all reads from and writes to memory | ||
| B | barrier events | is a barrier | ||
| A | atomic events | is an atomic event | ||
| P | plain events | is not an atomic event | ||
| I | initial writes | is an initial write event | ||
Having defined these sets, it is now possible to write expressions of the form RW(e) as [R * W] & e. However, the simulation in the latter case may be less efficient, owing to the need to construct the intermediate relation [R * W].
In C++ and OpenCL models, the following sets are pre-defined.
| identifier | name | description | ||
| rmw | read-modify-writes | the set of all read-modify-write events | ||
| brmw | blocked read-modify-writes | events representing an attempted read-modify-write operation that has become stuck | ||
| F | fences | the set of all fences | ||
| acq | acquire | atomic events with “acquire” memory-order | ||
| rel | release | atomic events with “release” memory-order | ||
| acq_rel | acquire/release | atomic events with “acquire/release” memory-order | ||
| rlx | relaxed | atomic events with “relaxed” memory-order | ||
| sc | sequentially consistent | atomic events with “sequentially consistent” memory-order | ||
| na | non-atomics | non-atomic events | ||
In C++ models, the following sets are pre-defined.
| identifier | name | description | ||
| lk | locks | the set of all lock events | ||
| ls | successful locks | the set of all successful lock events | ||
| ul | unlocks | the set of all unlock events | ||
| con | consume | atomic events with “consume” memory-order | ||
| atomicloc | atomic locations | events acting on atomic locations | ||
| nonatomicloc | non-atomic locations | events acting on non-atomic locations | ||
| mutexloc | mutex locations | events acting on mutex locations | ||
In OpenCL models, the following sets are pre-defined.
| identifier | name | description | ||
| gF | global fences | the set of all global fences | ||
| lF | local fences | the set of all local fences | ||
| wi | work-item scope | events with “work-item” memory-scope | ||
| sg | sub-group scope | events with “sub-group” memory-scope | ||
| wg | work-group scope | events with “work-group” memory-scope | ||
| dev | device scope | events with “device” memory-scope | ||
| all_dev | all-devices scope | events with “all_svn_devices” memory-scope | ||