


Part I |
Traditionally, a litmus test is a small parallel program designed to exercise the memory model of a parallel, shared-memory, computer. Given a litmus test in assembler (X86 or Power) litmus runs the test.
Using litmus thus requires a parallel machine, which must additionally feature gcc and the pthreads library. At the moment, litmus is a prototype and has numerous limitations (recognised instructions, limited porting). Nevertheless, litmus should accept all tests produced by the companion diy tool and has been successfully used on Linux, MacOS and on AIX.
The authors of litmus are Luc Maranget and Susmit Sarkar. The present litmus is inspired from a prototype by Thomas Braibant (INRIA Rhône-Alpes) and Francesco Zappa Nardelli (INRIA Paris-Rocquencourt).
Consider the following (rather classical) classic.litmus litmus test for X86:
X86 classic
"Fre PodWR Fre PodWR"
{ x=0; y=0; }
P0 | P1 ;
MOV [y],$1 | MOV [x],$1 ;
MOV EAX,[x] | MOV EAX,[y] ;
exists (0:EAX=0 /\ 1:EAX=0)
A litmus test source has three main sections:
$ litmus classic.litmus
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Results for classic.litmus %
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
X86 classic
"Fre PodWR Fre PodWR"
{ x=0; y=0; }
P0 | P1 ;
MOV [y],$1 | MOV [x],$1 ;
MOV EAX,[x] | MOV EAX,[y] ;
exists (0:EAX=0 /\ 1:EAX=0)
Generated assembler
_litmus_P0_0_: movl $1,(%rcx)
_litmus_P0_1_: movl (%rsi),%eax
_litmus_P1_0_: movl $1,(%rsi)
_litmus_P1_0_: movl $1,(%rsi)
_litmus_P1_1_: movl (%rcx),%eax
Test classic Allowed
Histogram (4 states)
34 :>0:EAX=0; 1:EAX=0;
499911:>0:EAX=1; 1:EAX=0;
499805:>0:EAX=0; 1:EAX=1;
250 :>0:EAX=1; 1:EAX=1;
Ok
Witnesses
Positive: 34, Negative: 999966
Condition exists (0:EAX=0 /\ 1:EAX=0) is validated
Hash=eb447b2ffe44de821f49c40caa8e9757
Time classic 0.60
...
The litmus test is first reminded, followed by actual assembler
— the machine is an AMD64, in-line address references disappeared,
registers may change, and
assembler syntax is now more familiar.
The test has run one million times, producing one million final states,
or outcomes for the registers EAX of threads P0 and P1.
The test run validates the condition, with 34 positive witnesses.
With option -o <name.tar>, litmus does not run the test. Instead, it produces a tar archive that contains the C sources for the test.
Consider ppc-classic.litmus, a Power version of the previous test:
PPC ppc-classic
"Fre PodWR Fre PodWR"
{
0:r2=y; 0:r4=x;
1:r2=x; 1:r4=y;
}
P0 | P1 ;
li r1,1 | li r1,1 ;
stw r1,0(r2) | stw r1,0(r2) ;
lwz r3,0(r4) | lwz r3,0(r4) ;
exists (0:r3=0 /\ 1:r3=0)
Our target machine (ppc) runs MacOS, wich we specify with the -os option:
$ litmus -o /tmp/a.tar -os mac ppc-classic.litmus $ scp /tmp/a.tar ppc:/tmp
Then, on the remote machine ppc:
ppc$ mkdir classic && cd classic ppc$ tar xf /tmp/a.tar ppc$ ls Makefile comp.sh run.sh ppc-classic.c outs.c utils.c
Test is compiled by the shell script comp.sh (of by (Gnu) make, at user’s choice) and run by the shell script run.sh:
$ sh comp.sh $ sh run.sh ... Test ppc-classic Allowed Histogram (3 states) 3947 :>0:r3=0; 1:r3=0; 499357:>0:r3=1; 1:r3=0; 496696:>0:r3=0; 1:r3=1; Ok Witnesses Positive: 3947, Negative: 996053 Condition exists (0:r3=0 /\ 1:r3=0) is validated ...
As we see, the condition validates also on Power. Notice that compilation produces an executable file, ppc-classic.exe, which can be run directly, for a less verbose output.
Consider the additional test ppc-storefwd.litmus:
PPC ppc-storefwd
"DpdR Fre Rfi DpdR Fre Rfi"
{
0:r2=x; 0:r6=y;
1:r2=y; 1:r6=x;
}
P0 | P1 ;
li r1,1 | li r1,1 ;
stw r1,0(r2) | stw r1,0(r2) ;
lwz r3,0(r2) | lwz r3,0(r2) ;
xor r4,r3,r3 | xor r4,r3,r3 ;
lwzx r5,r4,r6 | lwzx r5,r4,r6 ;
exists (0:r3=1 /\ 0:r5=0 /\ 1:r3=1 /\ 1:r5=0)
To compile the two tests together, we can give two file names as arguments to litmus:
$ litmus -o /tmp/a.tar -os mac ppc-classic.litmus ppc-storefwd.litmus
Or, more conveniently, list the litmus sources in a file whose name starts with @:
$ cat @ppc ppc-classic.litmus ppc-storefwd.litmus $ litmus -o /tmp/a.tar -os mac @ppc
To run the test on the remote ppc machine, the same sequence of commands as in the one test case applies:
ppc$ tar xf /tmp/a.tar && make && sh run.sh ... Test ppc-classic Allowed Histogram (3 states) 4167 :>0:r3=0; 1:r3=0; 499399:>0:r3=1; 1:r3=0; 496434:>0:r3=0; 1:r3=1; Ok Witnesses Positive: 4167, Negative: 995833 Condition exists (0:r3=0 /\ 1:r3=0) is validated ... Test ppc-storefwd Allowed Histogram (4 states) 37 :>0:r3=1; 0:r5=0; 1:r3=1; 1:r5=0; 499837:>0:r3=1; 0:r5=1; 1:r3=1; 1:r5=0; 499912:>0:r3=1; 0:r5=0; 1:r3=1; 1:r5=1; 214 :>0:r3=1; 0:r5=1; 1:r3=1; 1:r5=1; Ok Witnesses Positive: 37, Negative: 999963 Condition exists (0:r3=1 /\ 0:r5=0 /\ 1:r3=1 /\ 1:r5=0) is validated ...
Now, the output of run.sh shows the result of two tests.
Users can control some of testing conditions. Those impact efficiency and outcome variability.
Sometimes one looks for a particular outcome
— for instance, one may seek to get the
outcome 0:r3=1; 1:r3=1; that is missing
in the previous experiment for test ppc-classical.
To that aim, varying test conditions may help.
Consider a test a.litmus designed to run on t threads P0,…, Pt−1. The structure of the executable a.exe that performs the experiment is as follows:
In cache mode the Tk threads are re-used. As a consequence, t threads only are forked.
How this array cell is accessed depends upon the memory mode. In direct mode the array cell is accessed directly as x[i]; as a result, cells are accessed sequentially and false sharing effects are likely. In indirect mode the array cell is accessed by the means of a shuffled array of pointers; as a result we observed a much greater variability of outcomes.
If the preload mode is enabled, a preliminary loop of size s reads a random subset of the memory locations accessed by Pk. Preload have a noticeable effect.
The iterations performed by the different threads Tk may be unsynchronised, exactly synchronised by a pthread based barrier, or approximately synchronised by specific code. Absence of synchronisation may be interesting when t exceeds a. As a matter of fact, in this situation, any kind of synchronisation leads to prohibitive running times. However, for a large value of parameter s and small t we have observed spontaneous concurrent execution of some iterations amongst many. Pthread based barriers are exact but they are slow and in fact offers poor synchronisation for short code sequences. The approximate synchronisation is thus the preferred technique.
Hence, running a.exe produces n × r × s outcomes.
Parameters n, a, r and s can first be set directly while
invoking a.exe, using the appropriate command line options.
For instance, assuming t=2,
./a.exe -a 201 -r 10000 -s 1 and ./a.exe -n 1 -r 1 -s 1000000
will both produce one million outcomes, but the latter is probably
more efficient.
If our machine has 8 cores,
./a.exe -a 8 -r 1 -s 1000000 will yield 4 millions outcomes,
in a time that we hope not to exceed too much the one experienced
with ./a.exe -n 1.
Also observe that the memory allocated is roughly proportional
to n × s, while the number of Tk threads created will be
t × n × r (t × n in cache mode).
The run.sh shell script transmits its command line to all
the executable (.exe) files
it invokes, thereby providing a convenient means
to control testing condition for several tests.
Satisfactory test parameters are found by experimenting and
the control of executable files by command line options is designed for
that purpose.
Once satisfactory parameters are found, it is a nuisance to repeat them for every experiment. Thus, parameters a, r and s can also be set while invoking litmus, with the same command line options. In fact those settings command the default values of .exe files controls. Additionally, the synchronisation technique for iterations, the memory mode, and several others compile time parameters can be selected by appropriate litmus command line options. Finally, users can record frequently used parameters in configuration files.
We view affinity as a scheduler property that binds a (software, POSIX) thread to a given (hardware) logical processor. In the most simple situation a logical processor is a core. However in the presence of hyperthreading (x86) or simultaneous multi threading (SMT, Power) a given core can host several logical processors.
In our experience, binding the threads of test programs to selected logical processors yields sigificant speedups and, more importantly, greater outcome variety. We illustrate the issue by the means of an example.
We consider the test ppc-iriw-lwsync.litmus:
PPC ppc-iriw-lwsync
{
1:r2=x; 3:r2=y;
0:r2=y; 0:r4=x; 2:r2=x; 2:r4=y;
}
P0 | P1 | P2 | P3 ;
lwz r1,0(r2) | li r1,1 | lwz r1,0(r2) | li r1,1 ;
lwsync | stw r1,0(r2) | lwsync | stw r1,0(r2) ;
lwz r3,0(r4) | | lwz r3,0(r4) | ;
exists (0:r1=1 /\ 0:r3=0 /\ 2:r1=1 /\ 2:r3=0)
The test consists of four threads.
There are two writers (P1 and P3) that write the value
one into two different locations (x and y),
and two readers that read the contents of x and y
in different orders — P0 reads y first, while P2 reads
x first.
The load instructions lwz in reader threads are separated
by a lightweight barrier instruction lwsync.
The final condition exists (0:r1=1 /\ 0:r3=0 /\ 2:r1=1 /\ 2:r3=0)
characterises the situation where the reader threads see the writes
by P1 and P3 in opposite order.
The corresponding outcome 0:r1=1; 0:r3=0; 2:r1=1; 2:r3=0;
is the only non-sequential consistent (non-SC, see Part II) possible outcome.
By any reasonable memory model for Power, one expects the condition
to validate,
i.e. the non-SC outcome to show up.
The tested machine vargas is a Power 6 featuring 32 cores (i.e. 64 logical processors, since SMT is enabled) and running AIX in 64 bits mode. So as not to disturb other users, we run only one instance of the test, thus specifying four available processors. The litmus tool is absent on vargas. All these conditions command the following invocation of litmus, performed on our local machine:
$ litmus -r 1000 -s 1000 -a 4 -os aix -ws w64 ppc-iriw-lwsync.litmus -o ppc.tar $ scp ppc.tar vargas:/var/tmp
On vargas we unpack the archive and compile the test:
vargas$ tar xf /var/tmp/ppc.tar && sh comp.sh
Then we run the test:
vargas$ ./ppc-iriw-lwsync.exe -v Test ppc-iriw-lwsync Allowed Histogram (15 states) 152885:>0:r1=0; 0:r3=0; 2:r1=0; 2:r3=0; 35214 :>0:r1=1; 0:r3=0; 2:r1=0; 2:r3=0; 42419 :>0:r1=0; 0:r3=1; 2:r1=0; 2:r3=0; 95457 :>0:r1=1; 0:r3=1; 2:r1=0; 2:r3=0; 35899 :>0:r1=0; 0:r3=0; 2:r1=1; 2:r3=0; 70460 :>0:r1=0; 0:r3=1; 2:r1=1; 2:r3=0; 30449 :>0:r1=1; 0:r3=1; 2:r1=1; 2:r3=0; 42885 :>0:r1=0; 0:r3=0; 2:r1=0; 2:r3=1; 70068 :>0:r1=1; 0:r3=0; 2:r1=0; 2:r3=1; 1 :>0:r1=0; 0:r3=1; 2:r1=0; 2:r3=1; 41722 :>0:r1=1; 0:r3=1; 2:r1=0; 2:r3=1; 95857 :>0:r1=0; 0:r3=0; 2:r1=1; 2:r3=1; 30916 :>0:r1=1; 0:r3=0; 2:r1=1; 2:r3=1; 40818 :>0:r1=0; 0:r3=1; 2:r1=1; 2:r3=1; 214950:>0:r1=1; 0:r3=1; 2:r1=1; 2:r3=1; No Witnesses Positive: 0, Negative: 1000000 Condition exists (0:r1=1 /\ 0:r3=0 /\ 2:r1=1 /\ 2:r3=0) is NOT validated Hash=8ce05c9f86d49b2adfd5546bd471aa44 Time ppc-iriw-lwsync 1.33
The non-SC outcome does not show up.
Altering parameters may yield this outcome. In particular, we may try using all the available logical processors with option -a 64. Affinity control offers an alternative, which is enabled at compilation time with litmus option -affinity:
$ litmus ... -affinity incr1 ppc-iriw-lwsync.litmus -o ppc.tar $ scp ppc.tar vargas:/var/tmp
Option -affinity takes one argument (incr1 above) that specifies the increment used while allocating logical processors to test threads. Here, the (POSIX) threads created by the test (named T0, T1, T2 and T3 in Sec. 2.1) will get bound to logical processors 0, 1, 2, and 3, respectively.
Namely, by default, the logical processors are ordered as the sequence 0, 1, …, A−1 — where A is the number of available logical processors, which is inferred by the test executable1. Furthermore, logical processors are allocated to threads by applying the affinity increment while scanning the logical processor sequence. Observe that since the launch mode is changing (the default) threads Tk correspond to different test threads Pi at each run. The unpack compile and run sequence on vargas now yields the non-SC outcome, better outcome variety and a lower running time:
vargas$ tar xf /var/tmp/ppc.tar && sh comp.sh vargas$ ./ppc-iriw-lwsync.exe Test ppc-iriw-lwsync Allowed Histogram (16 states) 166595:>0:r1=0; 0:r3=0; 2:r1=0; 2:r3=0; 2841 :>0:r1=1; 0:r3=0; 2:r1=0; 2:r3=0; 19581 :>0:r1=0; 0:r3=1; 2:r1=0; 2:r3=0; 86307 :>0:r1=1; 0:r3=1; 2:r1=0; 2:r3=0; 3268 :>0:r1=0; 0:r3=0; 2:r1=1; 2:r3=0; 9 :>0:r1=1; 0:r3=0; 2:r1=1; 2:r3=0; 21876 :>0:r1=0; 0:r3=1; 2:r1=1; 2:r3=0; 79354 :>0:r1=1; 0:r3=1; 2:r1=1; 2:r3=0; 21406 :>0:r1=0; 0:r3=0; 2:r1=0; 2:r3=1; 26808 :>0:r1=1; 0:r3=0; 2:r1=0; 2:r3=1; 1762 :>0:r1=0; 0:r3=1; 2:r1=0; 2:r3=1; 100381:>0:r1=1; 0:r3=1; 2:r1=0; 2:r3=1; 83005 :>0:r1=0; 0:r3=0; 2:r1=1; 2:r3=1; 72241 :>0:r1=1; 0:r3=0; 2:r1=1; 2:r3=1; 98047 :>0:r1=0; 0:r3=1; 2:r1=1; 2:r3=1; 216519:>0:r1=1; 0:r3=1; 2:r1=1; 2:r3=1; Ok Witnesses Positive: 9, Negative: 999991 Condition exists (0:r1=1 /\ 0:r3=0 /\ 2:r1=1 /\ 2:r3=0) is validated Hash=8ce05c9f86d49b2adfd5546bd471aa44 Time ppc-iriw-lwsync 0.67
One may change the affinity increment with the command line option -i of executable files. For instance, one binds the test threads to logical processors 0, 2, 4 and 6 as follows:
vargas$ ./ppc-iriw-lwsync.exe -i 2 Test ppc-iriw-lwsync Allowed Histogram (15 states) 163114:>0:r1=0; 0:r3=0; 2:r1=0; 2:r3=0; 38867 :>0:r1=1; 0:r3=0; 2:r1=0; 2:r3=0; 48395 :>0:r1=0; 0:r3=1; 2:r1=0; 2:r3=0; 81191 :>0:r1=1; 0:r3=1; 2:r1=0; 2:r3=0; 38912 :>0:r1=0; 0:r3=0; 2:r1=1; 2:r3=0; 70574 :>0:r1=0; 0:r3=1; 2:r1=1; 2:r3=0; 30918 :>0:r1=1; 0:r3=1; 2:r1=1; 2:r3=0; 47846 :>0:r1=0; 0:r3=0; 2:r1=0; 2:r3=1; 69048 :>0:r1=1; 0:r3=0; 2:r1=0; 2:r3=1; 5 :>0:r1=0; 0:r3=1; 2:r1=0; 2:r3=1; 42675 :>0:r1=1; 0:r3=1; 2:r1=0; 2:r3=1; 82308 :>0:r1=0; 0:r3=0; 2:r1=1; 2:r3=1; 30264 :>0:r1=1; 0:r3=0; 2:r1=1; 2:r3=1; 43796 :>0:r1=0; 0:r3=1; 2:r1=1; 2:r3=1; 212087:>0:r1=1; 0:r3=1; 2:r1=1; 2:r3=1; No Witnesses Positive: 0, Negative: 1000000 Condition exists (0:r1=1 /\ 0:r3=0 /\ 2:r1=1 /\ 2:r3=0) is NOT validated Hash=8ce05c9f86d49b2adfd5546bd471aa44 Time ppc-iriw-lwsync 0.89
One observe that the non-SC outcome does not show up with the new affinity setting.
As illustrated by the previous example, both the running time and the outcomes of a test are sensitive to affinity settings. We measured running time for increasing values of the affinity increment from 0 (which disables affinity control) to 20, producing the following figure:
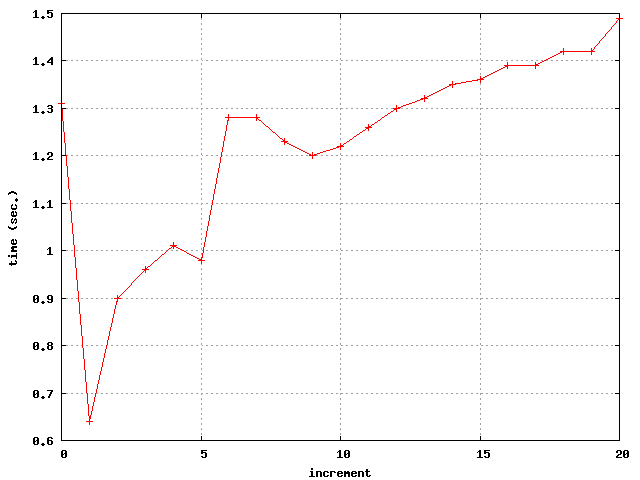
As regards outcome variety, we get all of the 16 possible outcomes only for an affinity increment of 1.
The differences in running times can be explained by reference to the mapping of logical processors to hardware. The machine vargas consists in four MCM’s (Multi-Chip-Module), each MCM consists in four “chips”, each chip consists in two cores, and each core may support two logical processors. As far as we know, by querying vargas with the AIX commands lsattr, bindprocessor and llstat, the MCM’s hold the logical processors 0–15, 16–31, 32–47 and 48–63, each chip holds the logical processors 4k, 4k+1, 4k+2, 4k+3 and each core holds the logical processors 2k, 2k+1.
The measure of running times for varying increments reveals two noticeable slowdowns: from an increment of 1 to an increment of 2 and from 5 to 6. The gap between 1 and 2 reveals the benefits of SMT for our testing application. An increment of 1 yields both the greatest outcome variety and the minimal running time. The other gap may perhaps be explained by reference to MCM’s: for a value of 5 the tests runs on the logical processors 0, 5, 10, 15, all belonging to the same MCM; while the next affinity increment of 6 results in running the test on two different MCM (0, 6, 12 on the one hand and 18 on the other).
As a conclusion, affinity control provides users with a certain level of control over thread placement, which is likely to yield faster tests when threads are constrained to run on logical processors that are “close” one to another. The best results are obtained when SMT is effectively enforced. However, affinity control is no panacea, and the memory system may be stressed by other means, such as, for instance, allocating important chunks of memory (option -s).
For specific experiments, the technique of allocating logical processors sequentially by following a fixed increment may be two rigid. litmus offers a finer control on affinity by allowing users to supply the logical processors sequence. Notice that most users will probably not need this advanced feature.
Anyhow, so as to confirm that testing ppc-iriw-lwsync benefits from not crossing chip boundaries, one may wish to confine its four threads to logical processors 16 to 19, that is to the first chip of the second MCM. This can be done by overriding the default logical processors sequence by an user supplied one given as an argument to command-line option -p:
vargas$ ./ppc-iriw-lwsync.exe -p 16,17,18,19 -i 1 Test ppc-iriw-lwsync Allowed Histogram (16 states) 186125:>0:r1=0; 0:r3=0; 2:r1=0; 2:r3=0; 1333 :>0:r1=1; 0:r3=0; 2:r1=0; 2:r3=0; 16334 :>0:r1=0; 0:r3=1; 2:r1=0; 2:r3=0; 83954 :>0:r1=1; 0:r3=1; 2:r1=0; 2:r3=0; 1573 :>0:r1=0; 0:r3=0; 2:r1=1; 2:r3=0; 9 :>0:r1=1; 0:r3=0; 2:r1=1; 2:r3=0; 19822 :>0:r1=0; 0:r3=1; 2:r1=1; 2:r3=0; 72876 :>0:r1=1; 0:r3=1; 2:r1=1; 2:r3=0; 20526 :>0:r1=0; 0:r3=0; 2:r1=0; 2:r3=1; 24835 :>0:r1=1; 0:r3=0; 2:r1=0; 2:r3=1; 1323 :>0:r1=0; 0:r3=1; 2:r1=0; 2:r3=1; 97756 :>0:r1=1; 0:r3=1; 2:r1=0; 2:r3=1; 78809 :>0:r1=0; 0:r3=0; 2:r1=1; 2:r3=1; 67206 :>0:r1=1; 0:r3=0; 2:r1=1; 2:r3=1; 94934 :>0:r1=0; 0:r3=1; 2:r1=1; 2:r3=1; 232585:>0:r1=1; 0:r3=1; 2:r1=1; 2:r3=1; Ok Witnesses Positive: 9, Negative: 999991 Condition exists (0:r1=1 /\ 0:r3=0 /\ 2:r1=1 /\ 2:r3=0) is validated Hash=8ce05c9f86d49b2adfd5546bd471aa44 Time ppc-iriw-lwsync 0.66
Thus we get results similar to the previous experiment on logical processors 0 to 3 (option -i 1 alone).
We may also run four simultaneous instances (-n 4, parameter n of section 2.1) of the test on the four available MCM’s:
vargas$ ./ppc-iriw-lwsync.exe -p 0,1,2,3,16,17,18,19,32,33,34,35,48,49,50,51 -n 4 -i 1 Test ppc-iriw-lwsync Allowed Histogram (16 states) ... Witnesses Positive: 80, Negative: 3999920 Condition exists (0:r1=1 /\ 0:r3=0 /\ 2:r1=1 /\ 2:r3=0) is validated Time ppc-iriw-lwsync 0.74
Obzserve that, for a negligible penalty in running time, the number of non-SC outcomes increases significantly.
By contrast, binding threads of a given instance of the test to different MCM’s results in poor running time and no non-SC outcome.
vargas$ ./ppc-iriw-lwsync.exe -p 0,1,2,3,16,17,18,19,32,33,34,35,48,49,50,51 -n 4 -i 4 Test ppc-iriw-lwsync Allowed Histogram (15 states) ... Witnesses Positive: 0, Negative: 4000000 Condition exists (0:r1=1 /\ 0:r3=0 /\ 2:r1=1 /\ 2:r3=0) is NOT validated Time ppc-iriw-lwsync 1.48
In the experiement above, the increment is 4, hence the logical processors allocated to the first instance of the test are 0, 16, 32, 48, of which indices in the logical processors sequence are 0, 4, 8, 12, respectively. The next allocated index in the sequence is 12+4 = 16. However, the sequence has 16 items. Wrapping around yields index 0 which happens to be the same as the starting index. Then, so as to allocate fresh processors, the starting index is incremented by one, resulting in allocating processors 1, 17, 33, 49 (indices 1, 5, 9, 13) to the second instance — see section 2.3 for the full story. Similarily, the third and fourth instances will get processors 2, 18, 34, 50 and 3, 19, 35, 51, respectively. Attentive readers may have noticed that the same experiment can be performed with option -i 16 and no -p option.
Finally, users should probably be aware that at least some versions of linux for x86 feature a less obvious mapping of logical processors to hardware. On a bi-processor, dual-core, 2-ways hyperthreading, linux, AMD64 machine, we have checked that logical processors residing on the same core are k and k+4, where k is an arbitray core number ranging from 0 to 3. As a result, a proper choice for favouring effective hyperthreading on such a machine is -i 4 (or -p 0,4,1,5,2,6,3,7 -i 1). More worthwhile noticing, perhaps, the straightforward choice -i 1 disfavours effective hyperthreading…
Any executable file produced by litmus accepts the following command line options.
If affinity control has been enabled at compilation time (by supplying option -affinity incr1 to litmus, for instance), the executable file produced by litmus accepts the following two command line options.
Logical processors are allocated test instance by test instance (parameter n of Sec. 2.1) and then thread by thread, scanning the logical processor sequence left-to-right by steps of the given increment. More precisely, assume a logical processor sequence P = p0, p1, …, pA−1 and an increment i. The first processor allocated is p0, then pi, then p2i etc, Indices in the sequence P are reduced modulo A so as to wrap around. The starting index of the allocation sequence (initially 0) is recorded, and coincidence with the index of the next processor to be allocated is checked. When coincidence occurs, a new index is computed, as the previous starting index plus one, which also becomes the new starting index. Allocation then proceeds from this new starting index. That way, all the processors in the sequence will get allocated to different threads naturally, provided of course that less than A threads are scheduled to run. See section 2.2.3 for an example with A=16 and i=4.
litmus takes file names as command line arguments. Those files are either a single litmus test, when having extension .litmus, or a list of file names, when prefixed by @. Of course, the file names in @files can themselves be @files.
There are many command line options. We describe the more useful ones:
The following options set the default values of the options of the executable files produced:
The following two options enable affinity control. Affnity control is not implemeted for MacOs.
Default for this -p option will let executable files compute the logical processor sequence themselves.
The following additional options control the various modes described in Sec. 2.1. Those cannot be changed without running litmus again:
Litmus compilation chain may slightly vary depending on the following parameters:
The syntax of configuration files is minimal: lines “key = arg” are interpreted as setting the value of parameter key to arg. Each parameter has a corresponding option, usually -key, except for single-letter options:
| option | key | arg |
| -a | avail | integer |
| -s | size_of_test | integer |
| -r | number_of_run | integer |
| -p | procs | list of integers |
As command line option are processed left-to-right, settings from a configuration file (option -mach) can be overridden by a later command line option. Some configuration files for the machines we have tested are present in the distribution. As an example here is the configuration file hpcx.cfg.
size_of_test = 2000 number_of_run = 20000 os = AIX ws = W32 # A node has 16 cores X2 (SMT) avail = 32
Lines introduced by # are comments and are thus ignored.
Configuration files are searched first in the current directory; then in any directory specified by setting the shell environment variable LITMUSDIR; and then in litmus installation directory, which is defined while compiling litmus.