


Part I |
Traditionally, a litmus test is a small parallel program designed to exercise the memory model of a parallel, shared-memory, computer. Given a litmus test in assembler (X86, X86_64, Power, ARM, MIPS, RISC-V), litmus7 runs the test.
Using litmus7 thus requires a parallel machine, which must additionally feature gcc and the pthreads library. Our tool litmus7 has some limitations especially as regards recognised instructions. Nevertheless, litmus7 should accept all tests produced by the companion test generators (see Part II) and has been successfully used on Linux, MacOS, AIX and Android.
Consider the following (rather classical, store buffering) SB.litmus litmus test for X86:
X86 SB
"Fre PodWR Fre PodWR"
{ x=0; y=0; }
P0 | P1 ;
MOV [x],$1 | MOV [y],$1 ;
MOV EAX,[y] | MOV EAX,[x] ;
exists (0:EAX=0 /\ 1:EAX=0)
A litmus test source has three main sections:
Run the test by (complete run log):
% litmus7 SB.litmus
%%%%%%%%%%%%%%%%%%%%%%%%%
% Results for SB.litmus %
%%%%%%%%%%%%%%%%%%%%%%%%%
X86 SB
"Fre PodWR Fre PodWR"
{x=0; y=0;}
P0 | P1 ;
MOV [x],$1 | MOV [y],$1 ;
MOV EAX,[y] | MOV EAX,[x] ;
exists (0:EAX=0 /\ 1:EAX=0)
Generated assembler
#START _litmus_P1
movl $1,(%r10)
movl (%r9),%eax
#START _litmus_P0
movl $1,(%r9)
movl (%r10),%eax
Test SB Allowed
Histogram (4 states)
40 *>0:EAX=0; 1:EAX=0;
499923:>0:EAX=1; 1:EAX=0;
500009:>0:EAX=0; 1:EAX=1;
28 :>0:EAX=1; 1:EAX=1;
Ok
Witnesses
Positive: 40, Negative: 999960
Condition exists (0:EAX=0 /\ 1:EAX=0) is validated
Hash=7dbd6b8e6dd4abc2ef3d48b0376fb2e3
Observation SB Sometimes 40 999960
Time SB 0.44
...
The litmus test is first reminded, followed by actual assembler
— the machine is a 64 bits one, in-line address references disappeared,
registers may change, and assembler syntax is now more familiar.
The test has run one million times, producing one million final states,
or outcomes for the registers EAX of threads P0 and P1.
The test run validates the condition, with 40 positive witnesses.
With option -o <name.tar>, litmus7 does not run the test. Instead, it produces a tar archive that contains the C sources for the test.
Consider SB-PPC.litmus, a Power version of the previous test:
PPC SB-PPC
"Fre PodWR Fre PodWR"
{
0:r2=x; 0:r4=y;
1:r2=y; 1:r4=x;
}
P0 | P1 ;
li r1,1 | li r1,1 ;
stw r1,0(r2) | stw r1,0(r2) ;
lwz r3,0(r4) | lwz r3,0(r4) ;
exists (0:r3=0 /\ 1:r3=0)
Our target machine (ppc) runs MacOS, which we specify with the -os option:
% litmus7 -o /tmp/a.tar -os mac SB-PPC.litmus % scp /tmp/a.tar ppc:/tmp
Then, on the remote machine ppc:
ppc% mkdir SB && cd SB ppc% tar xf /tmp/a.tar ppc% ls comp.sh Makefile outs.c outs.h README.txt run.sh SB-PPC.c show.awk utils.c utils.h
Test is compiled by the shell script comp.sh (or by (Gnu) make, at user’s choice) and run by the shell script run.sh:
ppc% sh comp.sh ppc% sh run.sh ... Test SB-PPC Allowed Histogram (3 states) 1784 *>0:r3=0; 1:r3=0; 498564:>0:r3=1; 1:r3=0; 499652:>0:r3=0; 1:r3=1; Ok Witnesses Positive: 1784, Negative: 998216 Condition exists (0:r3=0 /\ 1:r3=0) is validated Hash=4edecf6abc507611612efaecc1c4a9bc Observation SB-PPC Sometimes 1784 998216 Time SB-PPC 0.55 ...
(Complete run log.) As we see, the condition validates also on Power. Notice that compilation produces an executable file, SB-PPC.exe, which can be run directly, for a less verbose output.
Consider the additional test STFW-PPC.litmus:
PPC STFW-PPC
"Rfi PodRR Fre Rfi PodRR Fre"
{
0:r2=x; 0:r5=y;
1:r2=y; 1:r5=x;
}
P0 | P1 ;
li r1,1 | li r1,1 ;
stw r1,0(r2) | stw r1,0(r2) ;
lwz r3,0(r2) | lwz r3,0(r2) ;
lwz r4,0(r5) | lwz r4,0(r5) ;
exists
(0:r3=1 /\ 0:r4=0 /\ 1:r3=1 /\ 1:r4=0)
To compile the two tests together, we can give two file names as arguments to litmus:
$ litmus7 -o /tmp/a.tar -os mac SB-PPC.litmus STFW-PPC.litmus
Or, more conveniently, list the litmus sources in a file whose name starts with @:
$ cat @ppc SB-PPC.litmus STFW-PPC.litmus $ litmus7 -o /tmp/a.tar -os mac @ppc
To run the test on the remote ppc machine, the same sequence of commands as in the one test case applies:
ppc% tar xf /tmp/a.tar && make && sh run.sh ... Test SB-PPC Allowed Histogram (3 states) 1765 *>0:r3=0; 1:r3=0; 498741:>0:r3=1; 1:r3=0; 499494:>0:r3=0; 1:r3=1; Ok Witnesses Positive: 1765, Negative: 998235 Condition exists (0:r3=0 /\ 1:r3=0) is validated Hash=4edecf6abc507611612efaecc1c4a9bc Observation SB-PPC Sometimes 1765 998235 Time SB-PPC 0.57 ... Test STFW-PPC Allowed Histogram (4 states) 480 *>0:r3=1; 0:r4=0; 1:r3=1; 1:r4=0; 499560:>0:r3=1; 0:r4=1; 1:r3=1; 1:r4=0; 499827:>0:r3=1; 0:r4=0; 1:r3=1; 1:r4=1; 133 :>0:r3=1; 0:r4=1; 1:r3=1; 1:r4=1; Ok Witnesses Positive: 480, Negative: 999520 Condition exists (0:r3=1 /\ 0:r4=0 /\ 1:r3=1 /\ 1:r4=0) is validated Hash=92b2c3f6332309325000656d0632131e Observation STFW-PPC Sometimes 480 999520 Time STFW-PPC 0.56 ...
(Complete run log.) Now, the output of run.sh shows the result of two tests.
Users can control some of testing conditions. Those impact efficiency and outcome variability.
Sometimes one looks for a particular outcome
— for instance, one may seek to get the
outcome 0:r3=1; 1:r3=1; that is missing
in the previous experiment for test SB-PPC.
To that aim, varying test conditions may help.
Consider a test a.litmus designed to run on t threads P0,…, Pt−1. The structure of the executable a.exe that performs the experiment is as follows:
In cache mode the Tk threads are re-used. As a consequence, t threads only are forked.
How this array cell is accessed depends upon the memory mode. In direct mode the array cell is accessed directly as x[i]; as a result, cells are accessed sequentially and false sharing effects are likely. In indirect mode the array cell is accessed by the means of a shuffled array of pointers; as a result we observed a much greater variability of outcomes. Additionally, the increment of the main loop (of size s) can be set to a value or stride different from the default of one. Running a test several times with changing the stride value also proved quite effective in favouring outcome variability.
If the random preload mode is enabled, a preliminary loop of size s reads a random subset of the memory locations accessed by Pk. Preload has a noticeable effect and the random preload mode is enabled by default. Starting from version 5.0, we provide a more precise control over preloading memory locations — See Sec. 3.2.
The iterations performed by the different threads Tk may be unsynchronised, exactly synchronised by a pthread based barrier, or approximately synchronised by specific code. Absence of synchronisation may be interesting when t exceeds a. As a matter of fact, in this situation, any kind of synchronisation leads to prohibitive running times. However, for a large value of parameter s and small t we have observed spontaneous concurrent execution of some iterations amongst many. Pthread based barriers are exact but they are slow and in fact offers poor synchronisation for short code sequences. The approximate synchronisation is thus the preferred technique.
Starting from version 5.0, we provide a slightly altered user synchronisation mode: userfence, which alters user mode by executing memory fences to speedup write propagation. The new mode features overall better synchronisation, yielding dramatic improvements on some examples. However, outcome variability may suffer from this more accurate synchronisation, hence user mode remains the default.
More importantly, we provide an additional exact, timebase synchronisation technique: test threads will first synchronise using polling synchronisation barrier code, agree on a target timebase1 value and then loop reading the timebase until it exceeds the target value. This technique yields very good synchronisation and allows fine synchronisation tuning by assigning different starting delays to different threads — see Sec. 3.1. As ARM does not provide timebase counters, notice that “timebase” synchronisation for ARM silently degrades to synchronisation by the means of the polling synchronisation barrier.
Hence, running a.exe produces n × r × s outcomes.
Parameters n, a, r and s can first be set directly while
invoking a.exe, using the appropriate command line options.
For instance, assuming t=2,
./a.exe -a 20 -r 10k -s 1 and ./a.exe -n 1 -r 1 -s 1M
will both produce one million outcomes, but the latter is probably
more efficient.
If our machine has 8 cores,
./a.exe -a 8 -r 1 -s 1M will yield 4 millions outcomes,
in a time that we hope not to exceed too much the one experienced
with ./a.exe -n 1.
Also observe that the memory allocated is roughly proportional
to n × s, while the number of Tk threads created will be
t × n × r (t × n in cache mode).
The run.sh shell script transmits its command line to all
the executable (.exe) files
it invokes, thereby providing a convenient means
to control testing condition for several tests.
Satisfactory test parameters are found by experimenting and
the control of executable files by command line options is designed for
that purpose.
Once satisfactory parameters are found, it is a nuisance to repeat them for every experiment. Thus, parameters a, r and s can also be set while invoking litmus, with the same command line options. In fact those settings command the default values of .exe files controls. Additionally, the synchronisation technique for iterations, the memory mode, and several others compile time parameters can be selected by appropriate litmus7 command line options. Finally, users can record frequently used parameters in configuration files.
We view affinity as a scheduler property that binds a (software, POSIX) thread to a given (hardware) logical processor. In the most simple situation a logical processor is a core. However in the presence of hyper-threading (x86) or simultaneous multi threading (SMT, Power) a given core can host several logical processors.
In our experience, binding the threads of test programs to selected logical processors yields significant speedups and, more importantly, greater outcome variety. We illustrate the issue by the means of an example.
We consider the test ppc-iriw-lwsync.litmus:
PPC ppc-iriw-lwsync
{
0:r2=x; 1:r2=x; 1:r4=y;
2:r4=y; 3:r2=x; 3:r4=y;
}
P0 | P1 | P2 | P3 ;
li r1,1 | lwz r1,0(r2) | li r1,1 | lwz r1,0(r4) ;
stw r1,0(r2) | lwsync | stw r1,0(r4) | lwsync ;
| lwz r3,0(r4) | | lwz r3,0(r2) ;
exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0)
The test consists of four threads.
There are two writers (P0 and P2) that write the value
one into two different locations (x and y),
and two readers that read the contents of x and y
in different orders — P1 reads x first, while P3 reads
y first.
The load instructions lwz in reader threads are separated
by a lightweight barrier instruction lwsync.
The final condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0)
characterises the situation where the reader threads see the writes
by P0 and P2 in opposite order.
The corresponding outcome 1:r1=1; 1:r3=0; 3:r1=1; 3:r3=0;
is the only non-sequential consistent (non-SC, see Part II) possible outcome.
By any reasonable memory model for Power,
one expects the condition to validate,
i.e. the non-SC outcome to show up.
The tested machine vargas is a Power 6 featuring 32 cores (i.e. 64 logical processors, since SMT is enabled) and running AIX in 64 bits mode. So as not to disturb other users, we run only one instance of the test, thus specifying four available processors. The litmus7 tool is absent on vargas. All these conditions command the following invocation of litmus7, performed on our local machine:
$ litmus7 -r 1000 -s 1000 -a 4 -os aix -ws w64 ppc-iriw-lwsync.litmus -o ppc.tar $ scp ppc.tar vargas:/var/tmp
On vargas we unpack the archive and compile the test:
vargas% tar xf /var/tmp/ppc.tar && sh comp.sh
Then we run the test:
vargas% ./ppc-iriw-lwsync.exe Test ppc-iriw-lwsync Allowed Histogram (15 states) 163674:>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=0; 34045 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=0; 40283 :>1:r1=0; 1:r3=1; 3:r1=0; 3:r3=0; 95079 :>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=0; 33848 :>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=0; 72201 :>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=0; 32452 :>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=0; 43031 :>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=1; 73052 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=1; 1 :>1:r1=0; 1:r3=1; 3:r1=0; 3:r3=1; 42482 :>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=1; 90470 :>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=1; 30306 :>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=1; 43239 :>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=1; 205837:>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=1; No Witnesses Positive: 0, Negative: 1000000 Condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0) is NOT validated Hash=4fbfaafa51f6784d699e9bdaf5ba047d Observation ppc-iriw-lwsync Never 0 1000000 Time ppc-iriw-lwsync 1.32
The non-SC outcome does not show up.
Altering parameters may yield this outcome. In particular, we may try using all the available logical processors with option -a 64. Affinity control offers an alternative, which is enabled at compilation time with litmus7 option -affinity:
$ litmus7 ... -affinity incr1 ppc-iriw-lwsync.litmus -o ppc.tar $ scp ppc.tar vargas:/var/tmp
Option -affinity takes one argument (incr1 above) that specifies the increment used while allocating logical processors to test threads. Here, the (POSIX) threads created by the test (named T0, T1, T2 and T3 in Sec. 2.1) will get bound to logical processors 0, 1, 2, and 3, respectively.
Namely, by default, the logical processors are ordered as the sequence 0, 1, …, A−1 — where A is the number of available logical processors, which is inferred by the test executable2. Furthermore, logical processors are allocated to threads by applying the affinity increment while scanning the logical processor sequence. Observe that since the launch mode is changing (the default) threads Tk correspond to different test threads Pi at each run. The unpack compile and run sequence on vargas now yields the non-SC outcome, better outcome variety and a lower running time:
vargas% tar xf /var/tmp/ppc.tar && make vargas% ./ppc-iriw-lwsync.exe Test ppc-iriw-lwsync Allowed Histogram (16 states) 180600:>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=0; 3656 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=0; 18812 :>1:r1=0; 1:r3=1; 3:r1=0; 3:r3=0; 77692 :>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=0; 2973 :>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=0; 9 *>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=0; 28881 :>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=0; 75126 :>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=0; 20939 :>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=1; 30498 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=1; 1234 :>1:r1=0; 1:r3=1; 3:r1=0; 3:r3=1; 89993 :>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=1; 75769 :>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=1; 76361 :>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=1; 87864 :>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=1; 229593:>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=1; Ok Witnesses Positive: 9, Negative: 999991 Condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0) is validated Hash=4fbfaafa51f6784d699e9bdaf5ba047d Observation ppc-iriw-lwsync Sometimes 9 999991 Time ppc-iriw-lwsync 0.68
One may change the affinity increment with the command line option -i of executable files. For instance, one binds the test threads to logical processors 0, 2, 4 and 6 as follows:
vargas% ./ppc-iriw-lwsync.exe -i 2 Test ppc-iriw-lwsync Allowed Histogram (15 states) 160629:>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=0; 33389 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=0; 43725 :>1:r1=0; 1:r3=1; 3:r1=0; 3:r3=0; 93114 :>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=0; 33556 :>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=0; 64875 :>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=0; 34908 :>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=0; 43770 :>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=1; 64544 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=1; 4 :>1:r1=0; 1:r3=1; 3:r1=0; 3:r3=1; 54633 :>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=1; 92617 :>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=1; 34754 :>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=1; 54027 :>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=1; 191455:>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=1; No Witnesses Positive: 0, Negative: 1000000 Condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0) is NOT validated Hash=4fbfaafa51f6784d699e9bdaf5ba047d Observation ppc-iriw-lwsync Never 0 1000000 Time ppc-iriw-lwsync 0.92
One observes that the non-SC outcome does not show up with the new affinity setting.
One may also bind test thread to logical processors randomly with executable option +ra.
vargas% ./ppc-iriw-lwsync.exe +ra Test ppc-iriw-lwsync Allowed Histogram (15 states) ... No Witnesses Positive: 0, Negative: 1000000 Condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0) is NOT validated Hash=4fbfaafa51f6784d699e9bdaf5ba047d Observation ppc-iriw-lwsync Never 0 1000000 Time ppc-iriw-lwsync 1.85
As we see, the condition does not validate either with random affinity. As a matter of fact, logical processors are taken at random in the sequence 0, 1, …, 63; while the successful run with -i 1 took them in the sequence 0, 1, 2, 3. One can limit the sequence of logical processor with option -p, which takes a sequence of logical processors numbers as argument:
vargas% ./ppc-iriw-lwsync.exe +ra -p 0,1,2,3 Test ppc-iriw-lwsync Allowed Histogram (16 states) ... 8 *>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=0; ... Ok Witnesses Positive: 8, Negative: 999992 Condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0) is validated Hash=4fbfaafa51f6784d699e9bdaf5ba047d Observation ppc-iriw-lwsync Sometimes 8 999992 Time ppc-iriw-lwsync 0.70
The condition now validates.
As illustrated by the previous example, both the running time and the outcomes of a test are sensitive to affinity settings. We measured running time for increasing values of the affinity increment from 0 (which disables affinity control) to 20, producing the following figure:
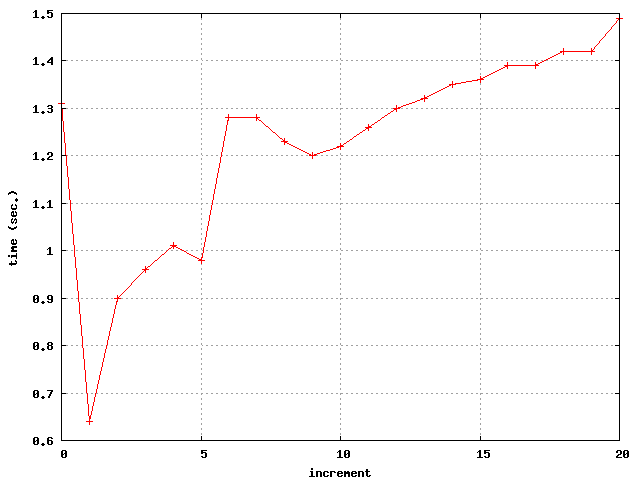
As regards outcome variety, we get all of the 16 possible outcomes only for an affinity increment of 1.
The differences in running times can be explained by reference to the mapping of logical processors to hardware. The machine vargas consists in four MCM’s (Multi-Chip-Module), each MCM consists in four “chips”, each chip consists in two cores, and each core may support two logical processors. As far as we know, by querying vargas with the AIX commands lsattr, bindprocessor and llstat, the MCM’s hold the logical processors 0–15, 16–31, 32–47 and 48–63, each chip holds the logical processors 4k, 4k+1, 4k+2, 4k+3 and each core holds the logical processors 2k, 2k+1.
The measure of running times for varying increments reveals two noticeable slowdowns: from an increment of 1 to an increment of 2 and from 5 to 6. The gap between 1 and 2 reveals the benefits of SMT for our testing application. An increment of 1 yields both the greatest outcome variety and the minimal running time. The other gap may perhaps be explained by reference to MCM’s: for a value of 5 the tests runs on the logical processors 0, 5, 10, 15, all belonging to the same MCM; while the next affinity increment of 6 results in running the test on two different MCM (0, 6, 12 on the one hand and 18 on the other).
As a conclusion, affinity control provides users with a certain level of control over thread placement, which is likely to yield faster tests when threads are constrained to run on logical processors that are “close” one to another. The best results are obtained when SMT is effectively enforced. However, affinity control is no panacea, and the memory system may be stressed by other means, such as, for instance, allocating important chunks of memory (option -s).
For specific experiments, the technique of allocating logical processors sequentially by following a fixed increment may be two rigid. litmus7 offers a finer control on affinity by allowing users to supply the logical processors sequence. Notice that most users will probably not need this advanced feature.
Anyhow, so as to confirm that testing ppc-iriw-lwsync benefits from not crossing chip boundaries, one may wish to confine its four threads to logical processors 16 to 19, that is to the first chip of the second MCM. This can be done by overriding the default logical processors sequence by an user supplied one given as an argument to command-line option -p:
vargas% ./ppc-iriw-lwsync.exe -p 16,17,18,19 -i 1 Test ppc-iriw-lwsync Allowed Histogram (16 states) 169420:>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=0; 1287 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=0; 17344 :>1:r1=0; 1:r3=1; 3:r1=0; 3:r3=0; 85329 :>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=0; 1548 :>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=0; 3 *>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=0; 27014 :>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=0; 75160 :>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=0; 19828 :>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=1; 29521 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=1; 441 :>1:r1=0; 1:r3=1; 3:r1=0; 3:r3=1; 93878 :>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=1; 81081 :>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=1; 76701 :>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=1; 93623 :>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=1; 227822:>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=1; Ok Witnesses Positive: 3, Negative: 999997 Condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0) is validated Hash=4fbfaafa51f6784d699e9bdaf5ba047d Observation ppc-iriw-lwsync Sometimes 3 999997 Time ppc-iriw-lwsync 0.63
Thus we get results similar to the previous experiment on logical processors 0 to 3 (option -i 1 alone).
We may also run four simultaneous instances (-n 4, parameter n of section 2.1) of the test on the four available MCM’s:
vargas% ./ppc-iriw-lwsync.exe -p 0,1,2,3,16,17,18,19,32,33,34,35,48,49,50,51 -n 4 -i 1 Test ppc-iriw-lwsync Allowed Histogram (16 states) ... 57 *>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=0; ... Ok Witnesses Positive: 57, Negative: 3999943 Condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0) is validated Hash=4fbfaafa51f6784d699e9bdaf5ba047d Observation ppc-iriw-lwsync Sometimes 57 3999943 Time ppc-iriw-lwsync 0.75
Observe that, for a negligible penalty in running time, the number of non-SC outcomes increases significantly.
By contrast, binding threads of a given instance of the test to different MCM’s results in poor running time and no non-SC outcome.
vargas% ./ppc-iriw-lwsync.exe -p 0,1,2,3,16,17,18,19,32,33,34,35,48,49,50,51 -n 4 -i 4 Test ppc-iriw-lwsync Allowed Histogram (15 states) ... Witnesses Positive: 0, Negative: 4000000 Condition exists (0:r1=1 /\ 0:r3=0 /\ 2:r1=1 /\ 2:r3=0) is NOT validated Time ppc-iriw-lwsync 1.48
In the experiment above, the increment is 4, hence the logical processors allocated to the first instance of the test are 0, 16, 32, 48, of which indices in the logical processors sequence are 0, 4, 8, 12, respectively. The next allocated index in the sequence is 12+4 = 16. However, the sequence has 16 items. Wrapping around yields index 0 which happens to be the same as the starting index. Then, so as to allocate fresh processors, the starting index is incremented by one, resulting in allocating processors 1, 17, 33, 49 (indices 1, 5, 9, 13) to the second instance — see section 2.3 for the full story. Similarly, the third and fourth instances will get processors 2, 18, 34, 50 and 3, 19, 35, 51, respectively. Attentive readers may have noticed that the same experiment can be performed with option -i 16 and no -p option.
Finally, users should probably be aware that at least some versions of Linux for x86 feature a less obvious mapping of logical processors to hardware. On a bi-processor, dual-core, 2-ways hyper-threading, Linux, AMD64 machine, we have checked that logical processors residing on the same core are k and k+4, where k is an arbitrary core number ranging from 0 to 3. As a result, a proper choice for favouring effective hyper-threading on such a machine is -i 4 (or -p 0,4,1,5,2,6,3,7 -i 1). More worthwhile noticing, perhaps, the straightforward choice -i 1 disfavours effective hyper-threading…
Most tests run by litmus7 are produced by the litmus test generators described in Part II. Those tests include meta-information that may direct affinity control. For instance we generate one test with the diyone7 tool, see Sec. 7.2. More specifically we generate IRIW+lwsyncs for Power (ppc-iriw-lwsync in the previous section) as follows:
% diyone7 -arch PPC -name IRIW+lwsyncs Rfe LwSyncdRR Fre Rfe LwSyncdRR Fre
We get the new source file IRIW+lwsyncs.litmus:
PPC IRIW+lwsyncs
"Rfe LwSyncdRR Fre Rfe LwSyncdRR Fre"
Prefetch=0:x=T,1:x=F,1:y=T,2:y=T,3:y=F,3:x=T
Com=Rf Fr Rf Fr
Orig=Rfe LwSyncdRR Fre Rfe LwSyncdRR Fre
{
0:r2=x;
1:r2=x; 1:r4=y;
2:r2=y;
3:r2=y; 3:r4=x;
}
P0 | P1 | P2 | P3 ;
li r1,1 | lwz r1,0(r2) | li r1,1 | lwz r1,0(r2) ;
stw r1,0(r2) | lwsync | stw r1,0(r2) | lwsync ;
| lwz r3,0(r4) | | lwz r3,0(r4) ;
exists
(1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0)
The relevant meta-information is the “Com” line that describes how test threads are related — for instance, thread 0 stores a value to memory that is read by thread 1, written “Rf” (see Part II for more details). Custom affinity control will tend to run threads related by “Rf” on “close” logical processors, where we can for instance consider that close logical processors belong to the same physical core (SMT for Power). This minimal logical processor topology is described by two litmus7 command-line option: -smt <n> that specifies n-way SMT; and -smt_mode (seq|end) that specifies how logical processors from the same core are numbered. For a 8-cores 4-ways SMT power7 machine we invoke litmus7 as follows:
% litmus7 -mem direct -smt 4 -smt_mode seq -affinity custom -o a.tar IRIW+lwsyncs.litmus
Notice that memory mode is direct and that the number of available logical processors is unspecified, resulting in running one instance of the test. More importantly, notice that affinity control is enabled -affinity custom, additionally specifying custom affinity mode.
We then upload the archive a.tar to our Power7 machine, unpack, compile and run the test:
power7% tar xmf a.tar
power7% make
...
power7% ./IRIW+lwsyncs.exe -v
./IRIW+lwsyncs.exe -v
IRIW+lwsyncs: n=1, r=1000, s=1000, +rm, +ca, p='0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31'
thread allocation:
[23,22,3,2] {5,5,0,0}
Option -v instructs the executable to show settings of the test harness: we see that one instance of the test is run (n=1), size parameters are reminded (r=1000, s=1000) and shuffling of indirect memory mode is performed (+rm). Affinity settings are also given: mode is custom (+ca) and the logical processor sequence inferred is given (-p 0,1,…,31). Additionally, the allocation of test threads to logical processors is given, as […], as well as the allocation of test threads to physical cores, as {…}.
Here is the run output proper:
Test IRIW+lwsyncs Allowed Histogram (15 states) 2700 :>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=0; 142 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=0; 37110 :>1:r1=0; 1:r3=1; 3:r1=0; 3:r3=0; 181257:>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=0; 78 :>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=0; 15 *>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=0; 103459:>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=0; 149486:>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=0; 30820 :>1:r1=0; 1:r3=0; 3:r1=0; 3:r3=1; 9837 :>1:r1=1; 1:r3=0; 3:r1=0; 3:r3=1; 2399 :>1:r1=1; 1:r3=1; 3:r1=0; 3:r3=1; 204629:>1:r1=0; 1:r3=0; 3:r1=1; 3:r3=1; 214700:>1:r1=1; 1:r3=0; 3:r1=1; 3:r3=1; 5186 :>1:r1=0; 1:r3=1; 3:r1=1; 3:r3=1; 58182 :>1:r1=1; 1:r3=1; 3:r1=1; 3:r3=1; Ok Witnesses Positive: 15, Negative: 999985 Condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0) is validated Hash=836eb3085132d3cb06973469a08098df Com=Rf Fr Rf Fr Orig=Rfe LwSyncdRR Fre Rfe LwSyncdRR Fre Affinity=[2, 3] [0, 1] ; (1,2) (3,0) Observation IRIW+lwsyncs Sometimes 15 999985 Time IRIW+lwsyncs 0.70
As we see, the test validates. Namely we observe the non-SC behaviour of IRIW in spite of the presence of two lwsync barriers. We may also notice, in the executable output some meta-information related to affinity: it reads that threads 2 and 3 on the one hand and threads 0 and 1 on the other are considered “close” (i.e. will run on the same physical core); while threads 1 and 2 on the one hand and threads 3 and 0 on the other are considered “far” (i.e. will run on different cores).
Custom affinity can be disabled by enabling another affinity mode. For instance with -i 0 we specify an affinity increment of zero. That is, affinity control is disabled altogether:
power7% ./IRIW+lwsyncs.exe -i 0 -v ./IRIW+lwsyncs.exe -i 0 -v IRIW+lwsyncs: n=1, r=1000, s=1000, +rm, i=0, p='0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31' Test IRIW+lwsyncs Allowed Histogram (15 states) ... No Witnesses Positive: 0, Negative: 1000000 Condition exists (1:r1=1 /\ 1:r3=0 /\ 3:r1=1 /\ 3:r3=0) is NOT validated Hash=836eb3085132d3cb06973469a08098df Com=Rf Fr Rf Fr Orig=Rfe LwSyncdRR Fre Rfe LwSyncdRR Fre Observation IRIW+lwsyncs Never 0 1000000 Time IRIW+lwsyncs 0.90
As we see, the test does not validate under those conditions.
Notice that section 19 describes a complete experiment on affinity control.
Any executable file produced by litmus7 accepts the following command line options.
Notice that options -s and -r accept a generalised syntax for their integer argument: when suffixed by k (resp. M) the integer gets multiplied by 103 (resp. 106).
The following options are accepted only for tests compiled in indirect memory mode (see Sec. 2.1):
The following option is accepted only for tests compiled with a specified stride value (see Sec. 2.1).
The following option is accepted when enabled at compile time:
If affinity control has been enabled at compilation time (for instance, by supplying option -affinity incr1 to litmus7), the executable file produced by litmus7 accepts the following command line options.
Notice that when custom affinity is not available, would it be that the test source lacked meta-information or that logical processor topology was not specified at compile-time, then +ca behaves as +ra.
Logical processors are allocated test instance by test instance (parameter n of Sec. 2.1) and then thread by thread, scanning the logical processor sequence left-to-right by steps of the given increment. More precisely, assume a logical processor sequence P = p0, p1, …, pA−1 and an increment i. The first processor allocated is p0, then pi, then p2i etc, Indices in the sequence P are reduced modulo A so as to wrap around. The starting index of the allocation sequence (initially 0) is recorded, and coincidence with the index of the next processor to be allocated is checked. When coincidence occurs, a new index is computed, as the previous starting index plus one, which also becomes the new starting index. Allocation then proceeds from this new starting index. That way, all the processors in the sequence will get allocated to different threads naturally, provided of course that less than A threads are scheduled to run. See Sec. 2.2.3 for an example with A=16 and i=4.
Timebase synchronisation of the testing loop iterations (see Sec. 2.1) is selected by litmus7 command line option -barrier timebase. In that mode, test threads will first synchronise using polling synchronisation barrier code, agree on a target timebase value and then loop reading the timebase until it exceeds the target value. Some tests demonstrate that timebase synchronisation is more precise than user synchronisation (-barrier user and default).
For instance, consider the x86 test 6.SB, a 6-thread analog of the SB test:
X86 6.SB
"Fre PodWR Fre PodWR Fre PodWR Fre PodWR Fre PodWR Fre PodWR"
{
}
P0 | P1 | P2 | P3 | P4 | P5 ;
MOV [x],$1 | MOV [y],$1 | MOV [z],$1 | MOV [a],$1 | MOV [b],$1 | MOV [c],$1 ;
MOV EAX,[y] | MOV EAX,[z] | MOV EAX,[a] | MOV EAX,[b] | MOV EAX,[c] | MOV EAX,[x] ;
exists
(0:EAX=0 /\ 1:EAX=0 /\ 2:EAX=0 /\ 3:EAX=0 /\ 4:EAX=0 /\ 5:EAX=0)
As for SB, the final condition of 6.SB identifies executions where each thread loads the initial value 0 of a location that is writtent into by another thread.
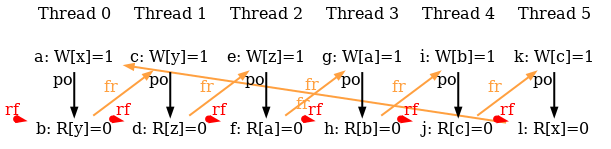
We first compile the test in user synchronisation mode, saving litmus7 output files into the directory R:
% mkdir -p R % litmus7 -barrier user -vb true -o R 6.SB.litmus % cd R % make
The additional command line option -vb true activates the printing of some timing information on synchronisations.
We then directly run the test executable 6.SB.exe:
% ./6.SB.exe Test 6.SB Allowed Histogram (62 states) 7569 :>0:EAX=1; 1:EAX=0; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; 8672 :>0:EAX=0; 1:EAX=1; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; ... 326 :>0:EAX=1; 1:EAX=0; 2:EAX=1; 3:EAX=1; 4:EAX=1; 5:EAX=1; 907 :>0:EAX=0; 1:EAX=1; 2:EAX=1; 3:EAX=1; 4:EAX=1; 5:EAX=1; No Witnesses Positive: 0, Negative: 1000000 Condition exists (0:EAX=0 /\ 1:EAX=0 /\ 2:EAX=0 /\ 3:EAX=0 /\ 4:EAX=0 /\ 5:EAX=0) is NOT validated Hash=107f1303932972b3abace3ee4027408e Observation 6.SB Never 0 1000000 Time 6.SB 0.85
The targeted outcome — reading zero in the EAX registers
of the 6 threads — is not observed.
We can observe synchronisation times for all tests runs
with the executable command line option +vb:
% ./6.SB.exe +vb 99999: 162768 420978 564546 -894 669468 99998: -93 3 81 -174 -651 99997: -975 -30 -33 93 -192 99996: 990 1098 852 1176 774 ...
We see five columns of numbers that list, for each test run, the starting delays of P1, P2 etc. with respect to P0, expressed in timebase ticks. Obviously, synchronisation is rather loose, there are always two threads whose starting delays differ of about 1000 ticks.
We now compile the same test in timebase synchronisation mode, saving litmus7 output files into the pre-existing directory RT:
% mkdir -p RT % litmus7 -barrier timebase -vb true -o RT 6.SB.litmus % cd RT % make
And we run the test directly (option -vb disable the printing of any synchronisation timing information):
% ./6.SB.exe -vb Test 6.SB Allowed Histogram (64 states) 60922 *>0:EAX=0; 1:EAX=0; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; 38299 :>0:EAX=1; 1:EAX=0; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; ... 598 :>0:EAX=0; 1:EAX=1; 2:EAX=1; 3:EAX=1; 4:EAX=1; 5:EAX=1; 142 :>0:EAX=1; 1:EAX=1; 2:EAX=1; 3:EAX=1; 4:EAX=1; 5:EAX=1; Ok Witnesses Positive: 60922, Negative: 939078 Condition exists (0:EAX=0 /\ 1:EAX=0 /\ 2:EAX=0 /\ 3:EAX=0 /\ 4:EAX=0 /\ 5:EAX=0) is validated Hash=107f1303932972b3abace3ee4027408e Observation 6.SB Sometimes 60922 939078 Time 6.SB 1.62
We now see that the test validates. Moreover all of the 64 possible outcomes are observed.
Timebase synchronisation works as follows: at every iteration,
By default the timebase delay δi is 211 = 2048 for all threads.
The precision of timebase synchronisation can be illustrated by enabling the printing of all synchronisation timings:
% ./6.SB.exe +vb 99999: 672294[1] 671973[1] 672375[1] 672144[1] 672303[1] 672222[1] 99998: 4524[1] 4332[1] 4446[1] 2052[65] 2064[73] 4095[1] ... 99983: 4314[1] 3036[1] 3141[1] 2769[1] 4551[1] 3243[1] 99982:* 2061[36] 2064[33] 2067[11] 2079[12] 2064[14] 2064[24] 99981: 2121[1] 2382[1] 2586[1] 2643[1] 2502[1] 2592[1] ...
For each test iteration and each thread, two numbers are shown (1) the last
timebase value read by and (2) (in brackets […]) how many iterations of loop 4. were performed.
Additionally a star “*” indicates the occurrence
of the targeted outcome.
Here, we see that a nearly perfect synchronisation can be achieved
(cf. line 99982: above).
Once timebase synchronisation have been selected (litmus7 option -barrier timebase), test executable behaviour can be altered by the following two command line options:
The litmus7 command line option -vb true (verbose barrier) governs the printing of synchronisation timings. It comes handy when choosing values for the -ta and -tb options. When set, the executable show synchronisation timings for outcomes that validate the test final condition. This default behaviour can be altered with the following two command line options:
Synchronisation timings are expressed in timebase ticks. The format depends on the synchronisation mode (litmus7 option -barrier). This section just gave two examples for user mode (timings are show as differences from thread P0); and for timebase mode (timings are shown as differences from a commonly agreed by all thread timebase value). Notice that, when affinity control is enabled, the running logical processors of threads are also shown.
Supplying the tags custom, static, static1 or static2 to litmus7 command line option -preload commands the insertion of cache prefetch or flush instructions before every test instance.
In custom mode the execution of such cache management instruction is under total user control, the other, “static”, modes offer less control to the user, for the sake of not altering test code proper.
Custom prefetch mode offers complete control over cache management instructions. Users enable this mode by supplying the command line option -preload custom to litmus7. For instance one may compile the x86 test 6.SB.litmus as follows:
% mkdir -p R % litmus7 -mem indirect -preload custom -o R 6.SB.litmus % cd R % make
Notice the test is compiled in indirect memory mode, in order to reduce false sharing effects.
The executable 6.SB.exe accepts two new command line options: -prf and -pra. Those options takes arguments that describe cache management instructions. The option -pra takes one letter that stands for a cache management instruction as we here describe:
All those cache management instructions are not provided by all architectures, in case some instruction is missing, the letters behave as follows:
With -pra X the commanded action applies to all threads and all variables, for instance:
% ./6.SB.exe -pra T
will perform a run where every test thread touches the test locations
that it refers to
(i.e. x and y for Thread 0, y
and z for Thread 1, etc.)
before executing test code proper.
Although one may achieve interesting results by using
this -pra option, the more selective
-prf option should prove more useful.
The -prf option takes a comma separated list of cache managment
directives.
A cache management directive is n:loc=X,
where n is a thread number, loc is a program variable,
and X is a cache management controle letter.
For instance, -prf 0:y=T instructs
thread 0 to touch location y.
More generally, having each thread of the test
6.SB to touch the memory location
it reads with its second instruction would favor reading the initial value
of these locations,
and thus validating
the final condition of the test
“(0:EAX=0 /\ 1:EAX=0 /\ 2:EAX=0 /\ 3:EAX=0 /\ 4:EAX=0 /\ 5:EAX=0)”.
Notice that those locations can be found by looking at the test code or at the diagram of the target execution. Let us have a try:
./6.SB.exe -prf 0:y=T,1:z=T,2:a=T,3:b=T,4:c=T,5:x=T Test 6.SB Allowed Histogram (63 states) 10 *>0:EAX=0; 1:EAX=0; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; ... Witnesses Positive: 10, Negative: 999990 ... Prefetch=0:y=T,1:z=T,2:a=T,3:b=T,4:c=T,5:x=T ...
As can be seen, the final condition is validated. Also notice that the prefetch directives used during the run are reminded. If given several times, -prf options cumulate, the rightmost directives taking precedence in case of ambiguity. As a consequence, one may achieve the same prefetching effect as above with:
% ./6.SB.exe -prf 0:y=T -prf 1:z=T -prf 2:a=T -prf 3:b=T -prf 4:c=T -prf 5:x=T
The source code of tests may include prefetch directives as metadata
prefixed with “Prefetch=”.
In particular, the generators of the diy7
suite (see Part II) produce such metadata.
For instance in the case of the
6.SB test (generated source 6.SB+Prefetch.litmus),
this metadata reads:
Prefetch=0:x=F,0:y=T,1:y=F,1:z=T,2:z=F,2:a=T,3:a=F,3:b=T,4:b=F,4:c=T,5:c=F,5:x=T
That is, each thread flushes the location it stores to and touches each location it reads from. Notice that each thread starts with a memory location access (here a store) and ends with another (here a load). The idea simply is to accelerate the exit access (with a cache touch) while delaying the entry access (with a cache flush).
When prefetch metadata is available, it acts as the default of prefetch directives:
% litmus7 -mem indirect -preload custom -o R 6.SB+Prefetch.litmus % cd R % make
Then we run the test by:
% ./6.SB+Prefetch.exe Test 6.SB Allowed Histogram (63 states) 674 *>0:EAX=0; 1:EAX=0; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; ... Witnesses Positive: 674, Negative: 999326 ... Prefetch=0:x=F,0:y=T,1:y=F,1:z=T,2:a=T,2:z=F,3:a=F,3:b=T,4:b=F,4:c=T,5:c=F,5:x=T ...
One may notice that the prefetch directives from the source file medata found its way to the test executable.
As with any kind of metadata, one can change the prefetch metadata by editing the litmus source file, or better by using the -hints command line option. The -hints command line option takes a filename as argument. This file is a mapping that associates new metadata to test names. As an example, we reverse diy7 scheme for cache management directives: accelerating entry accesses and delaying exit accesses:
% cat map.txt 6.SB Prefetch=0:x=W,0:y=F,1:y=W,1:z=F,2:a=F,2:z=W,3:a=W,3:b=F,4:b=W,4:c=F,5:c=W,5:x=F % litmus7 -mem indirect -preload custom -hints map.txt -o R 6.SB.litmus % cd R % make ... % ./6.SB.exe Test 6.SB Allowed Histogram (63 states) 24 *>0:EAX=0; 1:EAX=0; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; ... Prefetch=0:x=W,0:y=F,1:y=W,1:z=F,2:a=F,2:z=W,3:a=W,3:b=F,4:b=W,4:c=F,5:c=W,5:x=F ...
As we see above, the final condition validates. It does so in spite of the apparently unfavourable cache management directives.
We can experiment further without recompilation, by using the -pra and -prf command line options of the test executable. Those are parsed left-to-right, so that we can (1) cancel any default cache management directive with -pra I and (2) enable cache touch for the stores:
% ./6.SB.exe -pra I -prf 0:x=W -prf 1:y=W -prf 2:z=W -prf 3:a=W -prf 4:b=W -prf 5:c=W Test 6.SB Allowed ... Witnesses Positive: 0, Negative: 1000000 ... Prefetch=0:x=W,1:y=W,2:z=W,3:a=W,4:b=W,5:c=W
As we see, the final condition does not validate.
By contrast, flushing or touching the locations that the threads load permit to repetitively achieve validation:
chi% ./6.SB.exe -pra I -prf 0:y=F -prf 1:z=F -prf 2:a=F -prf 3:b=F -prf 4:c=F -prf 5:x=F Test 6.SB Allowed Histogram (63 states) 211 *>0:EAX=0; 1:EAX=0; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; ... % ./6.SB.exe -pra I -prf 0:y=T -prf 1:z=T -prf 2:a=T -prf 3:b=T -prf 4:c=T -prf 5:x=T Test 6.SB Allowed Histogram (63 states) 10 *>0:EAX=0; 1:EAX=0; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; ...
As a conclusion, interpreting the impact of cache management directives is not easy. However, custom preload mode (litmus command line option -preload custom) and test executable options -pra and -prf allow experimentation on specific tests.
Custom prefetch mode comes handy when one wants to tailor cache management directives for a particular test. In practice, we run batches of tests using source metadata for prefetch directives. In such a setting, the code that interprets the prefetch directives is useless, as we do not use the -prf option of the test executables. As this code get executed before each test thread code, it may impact test results. It is desirable to supress this code from test executables, still performing cache management instructions. To that aim, litmus7 provides some “static” preload modes, enabled with command line options -preload static, -preload static1 and -preload static2.
In the former mode -preload static and without any further user
intervention, each test thread executes the cache management
instructions commanded by the Prefetch metadata:
% mkdir -p S % litmus7 -mem indirect -preload static -o R 6.SB+Prefetch.litmus % make -C S % S/6.SB+Prefetch.exe Test 6.SB Allowed Histogram (63 states) 804 *>0:EAX=0; 1:EAX=0; 2:EAX=0; 3:EAX=0; 4:EAX=0; 5:EAX=0; ... Observation 804 999196 ...
As we can see above, the effect of the cache management instructions looks more favorable than in custom preload mode.
Users still have a limited control on the execution of cache management instructions: produced executable accept a new -prs <n> option, which take a positive or null integer as argument. Then, each test thread executes the cache management instructions commanded by source metadata with probability 1/n, the special value n=0 disabling prefetch altogether. The default for the -prs options is “1” (always execute the cache management instructions). Let us try:
% S/6.SB+Prefetch.exe -prs 0 | grep Observation Observation 6.SB Never 0 1000000 % S/6.SB+Prefetch.exe -prs 1 | grep Observation Observation 6.SB Sometimes 901 999099 % S/6.SB+Prefetch.exe -prs 2 | grep Observation Observation 6.SB Sometimes 29 999971 % S/6.SB+Prefetch.exe -prs 3 | grep Observation Observation 6.SB Sometimes 16 999984
In those experiments we show the “Observation” field of litmus7
output: this field gives the count of outcomes that validate the final
condition, followed by the count of outcomes that do not validate
the final condition. The above counts confirm that
cache management instructions favor validation.
The remaining preload modes static1 and static2 are similar, except that they produce executable files that do not accept the -prs option. Furthermore, in the former mode -preload static1 cache management instructions are always executed, while in the latter mode -preload static2 cache management instructions are executed with probability 1/2. Those modes thus act as pure static mode (litmus7 option -preload static), with runtime options -prs 1 and -prs 2 respectively. Moreover, as the test scaffold includes no code to interpret the -prs <n> switch, the test code is less perturbed. In practice and for the 6.SB example, there is little difference:
% mkdir -p S1 S2 % litmus7 -mem indirect -preload static1 -o S1 6.SB+Prefetch.litmus % litmus7 -mem indirect -preload static2 -o S2 6.SB+Prefetch.litmus % make -C S1 && make -C S2 ... % S1/6.SB+Prefetch.exe | grep Observation Observation 6.SB Sometimes 1119 998881 % S2/6.SB+Prefetch.exe | grep Observation Observation 6.SB Sometimes 16 999984
litmus7 takes file names as command line arguments. Those files are either a single litmus test, when having extension .litmus, or a list of file names, when prefixed by @. Of course, the file names in @files can themselves be @files.
There are many command line options. We describe the more useful ones:
The argument qemu instruct the shell script to use the qemu
emulator. The QEMU environment variable must be defined to the
emulator path before running the run.sh script, as in (sh syntax): QEMU=qemu sh run.sh.
The following options set the default values of the options of the executable files produced:
The following additional options control the various modes described in Sec. 2.1, and more. Those cannot be changed without running litmus7 again:
The following option commands affinity control:
Notice that affinity control is not implemented for MacOs.
The following options are significant when affinity control is enabled. Otherwise they are silent no-ops.
Custom affinity control (see Sec. 2.2.4) is enabled, first by enabling affinity control (e.g. with -affinity …), and then by specifying a logical processor topology with options -smt and -smt_mode.
Notice that custom affinity works only for those tests that include the proper meta-information. Otherwise, custom affinity silently degrades to random affinity.
Finally, a few miscellaneous options are documented:
This feature may prove useful for measuring running times that are not too much perturbed by the test harness, in combination with options -s 1 -r 1.
This feature may prove useful for analysing the synchronisation behaviour of a specific test, see Sec. 3.1.
Litmus compilation chain may slightly vary depending on the following parameters:
Some items in the source of tests can be changed at the very last moment. The new items are defined in mapping files whose names are arguments to the appropriate command line options. Mapping files simply are lists of pairs, with one line starting with a test name, and the rest of line defining the changed item. The changed item may also contain several lines: in that case it should be included in double quotes “".”.
exists,
kind Forbid being ~exists
and kind Require being forall.
Observe that the rename mapping is applied first. As a result kind or condition change must refer to new names. For instance, we can highlight that a X86 machine is not sequentially consistent by first renaming SB into SB+SC, and then changing the final condition. The new condition expresses that the first instruction (a store) of one of the threads must come first:
| rename.txt | cond.txt | |
SB SB+SC | SB+SC "forall (0:EAX=1 \/ 1:EAX=1)" | |
Then, we run litmus:
% litmus7 -mach x86 -rename rename.txt -conds cond.txt SB.litmus
%%%%%%%%%%%%%%%%%%%%%%%%%
% Results for SB.litmus %
%%%%%%%%%%%%%%%%%%%%%%%%%
X86 SB+SC
"Fre PodWR Fre PodWR"
{x=0; y=0;}
P0 | P1 ;
MOV [x],$1 | MOV [y],$1 ;
MOV EAX,[y] | MOV EAX,[x] ;
forall (0:EAX=1 \/ 1:EAX=1)
Generated assembler
#START _litmus_P1
movl $1,(%r8,%rdx)
movl (%rdx),%eax
#START _litmus_P0
movl $1,(%rdx)
movl (%r8,%rdx),%eax
Test SB+SC Required
Histogram (4 states)
39954 *>0:EAX=0; 1:EAX=0;
3979407:>0:EAX=1; 1:EAX=0;
3980444:>0:EAX=0; 1:EAX=1;
195 :>0:EAX=1; 1:EAX=1;
No
Witnesses
Positive: 7960046, Negative: 39954
Condition forall (0:EAX=1 \/ 1:EAX=1) is NOT validated
Hash=7dbd6b8e6dd4abc2ef3d48b0376fb2e3
Observation SB+SC Sometimes 7960046 39954
Time SB+SC 0.48
One sees that the test name and final condition have changed.
The syntax of configuration files is minimal: lines “key = arg” are interpreted as setting the value of parameter key to arg. Each parameter has a corresponding option, usually -key, except for single-letter options:
| option | key | arg |
| -a | avail | integer |
| -s | size_of_test | integer |
| -r | number_of_run | integer |
| -p | procs | list of integers |
| -l | loop | integer |
Notice that litmus7 in fact accepts long versions of options (e.g. -avail for -a).
As command line option are processed left-to-right, settings from a configuration file (option -mach) can be overridden by a later command line option. Some configuration files for the machines we have tested are present in the distribution. As an example here is the configuration file hpcx.cfg.
size_of_test = 2000 number_of_run = 20000 os = AIX ws = W32 # A node has 16 cores X2 (SMT) avail = 32
Lines introduced by # are comments and are thus ignored.
Configuration files are searched first in the current directory; then in any directory specified by setting the shell environment variable LITMUSDIR; and then in litmus installation directory, which is defined while compiling litmus7.
The tool klitmus7 is specialised for running kernel tests as kernel modules. Kernel modules are object files that can be loaded dynamically in a running kernel. The modules are then launched by reading the pseudo-file /proc/litmus.
Kernel tests are normally written in C, augmented with specific kernel macros. As an example, here is SB+onces.litmus, the kernel version of the store buffering litmus test:
C SB+onces
{}
P0(volatile int* y,volatile int* x) {
int r0;
WRITE_ONCE(*x,1);
r0 = READ_ONCE(*y);
}
P1(volatile int* y,volatile int* x) {
int r0;
WRITE_ONCE(*y,1);
r0 = READ_ONCE(*x);
}
exists (0:r0=0 /\ 1:r0=0)
As can be seen above, C litmus tests are formatted differently from assembler
tests: the code of threads is presented as functions, not as columns of
instructions. One may also notice that the test uses the kernel macros
WRITE_ONCE (guaranteed memory write) and READ_ONCE
(guaranteed memory read).
The tool klitmus7 offers only the cross compilation mode: i.e., klitmus7 translates the tests to some C files, plus Makefile and run script (run.sh).
% klitmus7 -o X.tar SB+onces.litmus
The above command outputs the archive X.tar.
Then, users compile the contents of the archive on the target machine, which need not be the machine where klitmus7 has run.
% mkdir -p X && cd X && tar xmf ../X.tar % make make make -C /lib/modules/3.13.0-108-generic/build/ M=/tmp/X modules make[1]: Entering directory `/usr/src/linux-headers-3.13.0-108-generic' CC [M] /tmp/X/litmus000.o Building modules, stage 2. MODPOST 1 modules CC /tmp/X/litmus000.mod.o LD [M] /tmp/X/litmus000.ko make[1]: Leaving directory `/usr/src/linux-headers-3.13.0-108-generic'
Notice that the final compilation relies on kernel headers being installed.
One then run the test. This step must be performed with root privileges, and requires the insmod and rmmod commands to be installed. We get:
% sudo sh run.sh Fri Aug 18 16:37:43 CEST 2017 Compilation command: klitmus7 -o X.tar SB+onces.litmus OPT= uname -r=3.13.0-108-generic Test SB+onces Allowed Histogram (4 states) 184992 *>0:r0=0; 1:r0=0; 909016 :>0:r0=1; 1:r0=0; 858961 :>0:r0=0; 1:r0=1; 47031 :>0:r0=1; 1:r0=1; Ok Witnesses Positive: 184992, Negative: 1815008 Condition exists (0:r0=0 /\ 1:r0=0) is validated Hash=2487db0f8d32aeb7ec0eacf5d0e301d7 Observation SB+onces Sometimes 184992 1815008 Time SB+onces 0.18 Fri Aug 18 16:37:43 CEST 2017
Output is similar to litmus7 output. One sees that the store buffer idiom is also observed in kernel mode.
In this simple example, we compile and run one single test. However, usual practice is, as it is for litmus7, to compile and run several tests at once. One achieves this naturally, by supplying several source files as command line arguments to klitmus7, or by using index files, see Sec 4.
The value of some test parameters (see Sec.2) can be set differently from defaults. This change is performed by the means of a key value interface.4 For instance, one sets the number of threads devoted to the test, the size of a run and the number of runs by using keywords avail, size and nruns, respectively:
% sudo sh run.sh avail=2 size=100 nruns=1 Mon Aug 21 11:04:12 CEST 2017 Compilation command: klitmus7 -o /tmp/X.tar SB+onces.litmus OPT=avail=2 size=100 nruns=1 uname -r=3.13.0-108-generic Test SB+onces Allowed Histogram (3 states) 12 *>0:r0=0; 1:r0=0; 48 :>0:r0=1; 1:r0=0; 40 :>0:r0=0; 1:r0=1; Ok Witnesses Positive: 12, Negative: 88 Condition exists (0:r0=0 /\ 1:r0=0) is validated Hash=2487db0f8d32aeb7ec0eacf5d0e301d7 Observation SB+onces Sometimes 12 88 Time SB+onces 0.00 Mon Aug 21 11:04:12 CEST 2017
The kernel modules produced by klitmus7 can be controlled by using the following keys=<int> settings. The default values of those parameters are set at compile time, by the means of command line options passed to klitmus7, see below.
Otherwise, ninst instance of each test is run. However, if the total number of threads used by a given test exceeds the number of online logical processors of the machine, the test is not run.
If this parameter is zero (or exceeds the number of online logical processors) then it is changed to the number of online logical processors of the machine. Finally, avail divided by the number of threads in test are run. Since this is euclidean division the resulting number of instances can be zero. In that case, the test is not run.
It is important to notice that the values of keywords are integers in a strict sense. Namely, the generalized syntax of integer (such as 10k, 1M etc.) is not accepted. Moreover, except in the affinity case, where negative values are accepted, only positive (or null) values are accepted.
Given that klitmus7 purpose is running kernel litmus tests, klitmus7 accepts tests written (1) in C or (2) in LISA, an experimental generic assembler langage.
As regards options klitmus7 accepts a restricted subset of the options accepted by litmus7, plus a few specific options.
Most of these options set the default values of the parameters described above.
syncronize_rcu to
synchronize_expedited (which may be much faster).
Default is true.
The non-standard modes are selected by litmus7 options -mode presi and -mode kvm.
In standard mode, system threads are spawned frequently — see Section 2.1. By contrast, in presi mode, harness threads are created once for all and then collaborate to execute litmus tests, a technique better adapted to running tests over limiter system support. Non-standard modes also permit finer control over some of test parameters and the collection of statistics on their effect.
During test run, each harness thread runs various tests threads, with various parameters being selected randomly. For instance, consider the following test R:
X86_64 R
{ }
P0 | P1 ;
movl $1,(x) | movl $2,(y) ;
movl $1,(y) | movl (x),%eax ;
exists ([y]=2 /\ 1:rax=0)
On a X86_64 machine with four cores two-ways hyper-threaded cores, we compile the test R in presi mode as follows:
% mkdir -p R % litmus7 -mach x86_64 -mode presi -avail 8 -o R R.litmus % cd R % make ...
Namely, the machine has 8 “logical” cores, i.e 4 two-way hyper-threaded cores. Hence the harness spawns 8 threads, whether those threads being attached to hardware logical cores or not depends on the target system offering affinity control (Linux) or not (MacOs).
We now run the test:
% ./R.exe -s 1k -r 1k
Test R Allowed
Histogram (4 states)
1889769:>1:rax=0; [y]=1;
1653920:>1:rax=1; [y]=2;
322740*>1:rax=0; [y]=2;
133571:>1:rax=1; [y]=1;
Ok
Witnesses
Positive: 322740, Negative: 3677260
Condition exists ([y]=2 /\ 1:rax=0) is validated
Hash=b66b3ce129b44b61416afa21c7cc6972
Observation R Sometimes 322740 3677260
Topology 56913 :> part=0 [[0],[1]]
Topology 265827:> part=1 [[0,1]]
Vars 205786:> {xp=0}
Vars 116954:> {xp=1}
Cache 86602 :> {c_0_x=0, c_0_y=1, c_1_x=0, c_1_y=0}
Cache 67620 :> {c_0_x=0, c_0_y=2, c_1_x=0, c_1_y=0}
Cache 41920 :> {c_0_x=0, c_0_y=2, c_1_x=0, c_1_y=1}
Cache 51438 :> {c_0_x=2, c_0_y=1, c_1_x=0, c_1_y=0}
Cache 49888 :> {c_0_x=2, c_0_y=2, c_1_x=0, c_1_y=0}
Time R 0.85
First observe the command lines options “-s 1k -r 1k”, thereby setting the size parameter s and the number of runs r. The interpretation of these settings differ from standard mode: in presi mode and for each test instance, s experiments are performed for a given random allocation of test threads to harness threads. This process is performed r times, resulting in n × r × s experiments, where n is the number of test instances (see Section 2.1).
In test output above. we see that the final state of the test is observed about 323k times over four billions tries. More significantly, we see some record of successful parameters. Each line consists in a number of occurrences of and of a parameter choice, called parameter statistics. For instance, the first line “Topology 56913 :> part=0 [[0],[1]]” signals there are about 57k occurrences of the target outcome 1:rax=0; [y]=2; with topology parameter part=0. We now list parameters:
... # Standard Intel parameters smt=2 ...Thus, “logical” core are grouped by two. Hence, the two threads of the R test can either be running on cores in the same group, or from different groups. This corresponds to parameters part=1 [[0,1]] and part=0 [[0],[1]], respectively.
As a distinctive feature of presi mode, users can set fixed values for parameters by giving settings on the command line. For instance, one can set the topology and vars parameters to their most productive values from a first test run:
% ./R.exe -s 1k -r 1k part=1 xp=0
Test R Allowed
...
Observation R Sometimes 660262 3339738
Topology 660262:> part=1 [[0,1]]
Vars 660262:> {xp=0}
Cache 387980:> {c_0_x=0, c_0_y=1, c_1_x=0, c_1_y=0}
Cache 272282:> {c_0_x=0, c_0_y=2, c_1_x=0, c_1_y=0}
Time R 0.52
We witness an improvement of productivity by a factor of two.
Most command line options were designed for standard mode first and presi mode is in some sense more automated. As a consequence, few command line settings apply to the presi mode: we have already seen the -r, -s and -a setting, of which interpretation significantly differs from standard mode.
All options related to affinity are ignored: topology variation applies even when harness threads cannot be attached to hardware threads. However, one can void the effect of topology variation with the option -smt 1 (resulting in as many groups as available harness threads), or by giving the same number argument to the options -smt and -a (resulting in one group).
The barrier setting option -barrier tb of Section 3.1 is effective. The timebase delay value is expressed in “ticks”, depends on the target architecture and can be changed at runtime with option -tb <num>. Moreover, this option introduces a new randomly selected parameter. The delay parameter of threads w.r.t. to the starting time of test thread T0, as a (possibly negative) number of one eighth of the timebase delay value in the interval [−4..4].
Option -driver C is also implemented. It commands to the production of one executable run.exe in place of one executable per test with the default -driver shell.
Observe that non-implemented options are silently ignored.
The kvm (or vmsa) mode is based upon the presi mode. This mode permits running tests at the system level under the control of the KVM virtualisation infrastructure, by using the adequate qemu virtual machine. To that aim, it leverages the pre-existing kvm-unit-tests framework, available for Linux boxes and, with a little effort, on ARM-based Apple machines. Our extension has been developed for ARM AArch64 and from now we shall consider this architecture. However, there is also a partial implementation for X86_64. Refer to kvm-unit-tests or to OS documentation for qemu with kvm support and kvm-unit-tests installation instructions (instructions for Debian Linux).
Let us consider the following two system tests MP-TTD+DMB.ST+DMB.LD and MP-TTD+DMB.ST+DSB-ISB:
AArch64 MP-TTD+DMB.ST+DMB.LD
EL0=P1
{
0:X2=TTD(x); 0:X1=(valid:1,oa:PA(x));
0:X8=y; 1:X8=y;
1:X3=x;
[TTD(x)]=(valid:0,oa:PA(x));
}
P0 | P1;
STR X1,[X2] | LDR W7,[X8] ;
DMB ST | DMB LD ;
MOV W7,#1 | L0: LDR W4,[X3];
STR W7,[X8] | ;
exists(1:X7=1 /\
Fault(P1:L0,x,MMU:Translation))
| AArch64 MP-TTD+DMB.ST+DSB-ISB
EL0=P1
{
[TTD(x)]=(valid:0,oa:PA(x));
0:X2=TTD(x);
0:X1=(valid:1,oa:PA(x));
1:X3=x;
0:X8=y; 1:X8=y;
}
P0 | P1;
STR X1,[X2] | LDR W7,[X8] ;
DMB ST | DSB SY ;
MOV W7,#1 | ISB ;
STR W7,[X8] | L0: LDR W4,[X3];
exists(1:X7=1 /\
Fault(P1:L0,x,MMU:Translation))
|
The tests are specific “message-passing tests” acting on the signal
location y and the data location x. However, instead
of changing the data content, we change its status or, more precisely,
its TTD (Translation Table Descriptors). That is, location x is
invalid initially and T0 restore validity with its first
instruction STR X1,[X2], where the register X1 holds
the valid descriptor and the register X2 points to the page table
entry of x. The thread T0 then signals by writing the
value one into the location y. Concurrently, T1 reads the
signal location y and then attemps to read x.
The final condition
exists(1:X7=1 /\ Fault(P1:L0,x,MMU:Translation)
describes the situation when the signal has been received by T1
(1:X7=1), while T1 has not yet noticed that T0 has made
accessing to x valid
— The atom Fault(P1:L0,x,MMU:Translation) corresponds to a
faulting attempt by T1 to read the location x.
The two tests differ by their synchronisation
instructions: MP-TTD+DMB.ST+DMB.LD is synchronised by fences
sufficient to synchronise the ordinary message passing test,
while MP-TTD+DMB.ST+DSB-ISB synchronisation is more
heavyweight.
Compilation to qemu binary file arguments is complex. For user convenience, we provide litmus configuration files kvm-aarch64.cfg (generic ARMv8.0), kvm-armv8.1.cfg (for ARMv8.1) and kvm-m1.cfg (for Apple machines). As an example, we target some ARMv8.0 machine MACH, with a functional gcc compiler and kvm-unit-tests installed in some homonymous directory. We execute litmus7 on another machine and run the tests on MACH following the usual “litmus-cross-compilation” scheme.
% litmus7 -mach kvm-aarch64 -variant fatal -o M.tar MP-TTD+DMB.ST+DMB.LD.litmus MP-TTD+DMB.ST+DSB-ISB.litmus % scp M.tar MACH:
Notice the -variant fatal option that controls fault management. Here, if some instruction faults, control is transferred at the end of thread code. See
On the target machine, we unpack the transferred archive into some sub-directory of the kvm-unit-tests installation, and compile the test:
mach% cd kvm-litmus-tests mach% mkdir -p M mach% cd M mach% tar xmf ../../M.tar mach% make ...
We are now ready to run the tests. It is important to observe that tests can be run from the kvm-unit-tests directory and only from there:
% sh M/run.sh ... Test MP-TTD+DMB.ST+DMB.LD Allowed Histogram (4 states) 70 *>1:X7=1; fault(P1:L0,x,MMU:Translation); 1975326:>1:X7=0; ~fault(P1:L0,x,MMU:Translation); 21197 :>1:X7=0; fault(P1:L0,x,MMU:Translation); 3407 :>1:X7=1; ~fault(P1:L0,x,MMU:Translation); Ok Witnesses Positive: 70, Negative: 1999930 Condition exists (1:X7=1 /\ fault(P1:L0,x,MMU:Translation)) is validated Hash=e6d0396aa32c40b307db5f6921404c07 EL0=P1 Observation MP-TTD+DMB.ST+DMB.LD Sometimes 70 1999930 Topology 70 :> part=0 [[0],[1]] Faults MP-TTD+DMB.ST+DMB.LD 21267 P1:21267 Time MP-TTD+DMB.ST+DMB.LD 15.14 ... Test MP-TTD+DMB.ST+DSB-ISB Allowed Histogram (3 states) 1991985:>1:X7=0; ~fault(P1:L0,x,MMU:Translation); 5938 :>1:X7=0; fault(P1:L0,x,MMU:Translation); 2077 :>1:X7=1; ~fault(P1:L0,x,MMU:Translation); No Witnesses Positive: 0, Negative: 2000000 Condition exists (1:X7=1 /\ fault(P1:L0,x,MMU:Translation)) is NOT validated Hash=18e9682c0e7ed43f7f059cbfc47d781d EL0=P1 Observation MP-TTD+DMB.ST+DSB-ISB Never 0 2000000 Faults MP-TTD+DMB.ST+DSB-ISB 5938 P1:5938 Time MP-TTD+DMB.ST+DSB-ISB 17.29 ...
The above log has been elided for brevity, complete log. We see that the lightweight synchronisation pattern of MP-TTD+DMB.ST+DMB.LD does not suffice to forbid the non-SC message passing execution, while the heavyweight synchronisation pattern of MP-TTD+DMB.ST+DSB-ISB does suffice.
Due to harness structure and kvm-unit-tests limited system support, litmus7 options and runtime controls are restricted. Harness structure is similar to one of presi mode, with the noticeable exception that each memory location resides in its own (virtual memory) page, where the memory location of the presi mode reside in cache lines. The following options are worth mentioning:
It is worth noticing that, once harness threads are selected according to their groups, allocation of test threads to them is performed randomly, unless the test executable is given the +fix option. For instance, considering a test with two threads T0 and T1 running on the above described machine, let us further assume the allocation of a test instance to the group {2,5}. Then, the two possible random allocations are { T0 → 2, T1 → 5} and { T0 → 5, T1 → 2}. With option +fix one only of those allocations is performed.
However notice that parameter statistics are not collected and thus not printed in -driver C mode.
Other miscellaneous options are implemented, such as -stdio (true|false), -hexa, -alloc (dynamic|static), … Non recognised options should be ignored silently.