


Part IV |
In the following experiment reports we describe both how we generate tests and how we run them on various machines under various conditions.
In this section we describe an experiment on changing the stride (cf Sec. 2.1). This usage pattern applies to many situations, where a series of test is compiled once and run many times under changing conditions.
We assume a directory tst-x86 (archive), that contains a series of litmus tests and an index file @all. Those tests where produced by the diy7 tool (see Sec. 8). They are two thread tests that exercise various relaxed behaviour of x86 machines. More specifically, diy7 is run as “diy -conf X.conf”, where X.conf is the following configuration file
-arch X86 -name X -safe Rfe,Fre,Wse,PodR*,PodWW,MFencedWR -relax PodWR,[Rfi,PodRR] -mix true -mode critical -size 5 -nprocs 2
As described in Sec. 12.5, diy7 will generate all critical cycles of size at most 5, built from the given lists of candidate relaxations, spanning other two threads, and including at least one occurrence of PodWR, [Rfi,PodRR] or both. In effect, as x86 machines follow the TSO model that relaxes write to read pairs, all produced tests should a priori validate.
We test some x86-64 machine, using the following x86-64.cfg litmus7 configuration file:
#Machine/OS specification os = linux word = w64 #Test parameters size_of_test = 1000 number_of_run = 10 memory = direct stride = 1
The number of available logical processors is unspecified, it thus defaults to 1, leading to running one instance of the test only (cf parameter a in Sec. 2.1)
We invoke litmus7 as follows, where run is a pre-existing empty directory:
% litmus7 -mach x86-64 -o run tst-x86/@all
The directory run now contains C-source files for the tests, as well as some additional files:
% ls run comp.sh outs.c README.txt utils.c X000.c X002.c X004.c X006.c Makefile outs.h run.sh utils.h X001.c X003.c X005.c
One notices a short README.txt file, two scripts to compile (com.sh) and run the tests (run.sh), and a Makefile. We use the latter to build test executables:
% cd run % make -j 8 gcc -Wall -std=gnu99 -fomit-frame-pointer -O2 -m64 -pthread -O2 -c outs.c gcc -Wall -std=gnu99 -fomit-frame-pointer -O2 -m64 -pthread -O2 -c utils.c gcc -Wall -std=gnu99 -fomit-frame-pointer -O2 -m64 -pthread -S X000.c ... gcc -Wall -std=gnu99 -fomit-frame-pointer -O2 -m64 -pthread -o X005.exe outs.o utils.o X005.s gcc -Wall -std=gnu99 -fomit-frame-pointer -O2 -m64 -pthread -o X006.exe outs.o utils.o X006.s rm X005.s X004.s X006.s X000.s X001.s X002.s X003.s
This builds the seven tests X000.exe to X006.exe.
The size parameters (size_of_test = 1000 and
number_of_run = 10) are rather small, leading to fast tests:
% ./X000.exe Test X000 Allowed Histogram (2 states) 5000 :>0:EAX=1; 0:EBX=1; 1:EAX=1; 1:EBX=0; 5000 :>0:EAX=1; 0:EBX=0; 1:EAX=1; 1:EBX=1; No ... Condition exists (0:EAX=1 /\ 0:EBX=0 /\ 1:EAX=1 /\ 1:EBX=0) is NOT validated ... Observation X000 Never 0 10000 Time X000 0.01
However, the test fails, in the sense that the relaxed outcome targeted by X000.exe is not observed, as can be seen quite easily from the “Observation Never…” line above .
To observe the relaxed outcome, it happens it suffices to change the stride value to 2:
% ./X000.exe -st 2 Test X000 Allowed Histogram (3 states) 21 *>0:EAX=1; 0:EBX=0; 1:EAX=1; 1:EBX=0; 4996 :>0:EAX=1; 0:EBX=1; 1:EAX=1; 1:EBX=0; 4983 :>0:EAX=1; 0:EBX=0; 1:EAX=1; 1:EBX=1; Ok ... Condition exists (0:EAX=1 /\ 0:EBX=0 /\ 1:EAX=1 /\ 1:EBX=0) is validated ... Observation X000 Sometimes 21 9979 Time X000 0.00
We easily perform a more complete experiment with the stride changing from 1 to 8, by running the run.sh script, which transmits its command line options to all test executables:
% for i in $(seq 1 8) > do > sh run.sh -st $i > X.0$i > done
Run logs are thus saved into files X.01 to X.08. The following table summarises the results:
| X.01 | X.02 | X.03 | X.04 | X.05 | X.06 | X.07 | X.08 | |
| X000 | 0/10k | 21/10k | 0/10k | 17/10k | 0/10k | 19/10k | 2/10k | 40/10k |
| X001 | 0/10k | 108/10k | 0/10k | 77/10k | 2/10k | 29/10k | 0/10k | 29/10k |
| X002 | 0/10k | 2/10k | 0/10k | 6/10k | 0/10k | 7/10k | 0/10k | 5/10k |
| X003 | 0/10k | 4/10k | 2/10k | 1/10k | 0/10k | 5/10k | 0/10k | 11/10k |
| X004 | 0/10k | 4/10k | 0/10k | 33/10k | 0/10k | 10/10k | 0/10k | 8/10k |
| X005 | 0/10k | 1/10k | 0/10k | 0/10k | 0/10k | 5/10k | 0/10k | 4/10k |
| X006 | 0/10k | 8/10k | 0/10k | 9/10k | 0/10k | 11/10k | 1/10k | 12/10k |
For every test and stride value cells show how many times the targeted relaxed outcome was observed/total number of outcomes. One sees that even stride value perfom better — noticeably 2, 6 and 8. Moreover variation of the stride parameters permits the observation of the relaxed outcomes targeted by all tests.
We can perform another, similar, experiment changing the s (size_of_test) and r (number_of_run) parameters.
Notice that the respective default values of s and r are
1000 and 10, as specified in the x86-64.cfg
configuration file.
We now try the following settings:
% sh run.sh -a 16 -s 10 -r 10000 > Y.01 % sh run.sh -a 16 -s 100 -r 1000 > Y.02 % sh run.sh -a 16 -s 1000 -r 100 > Y.03 % sh run.sh -a 16 -s 10000 -r 10 > Y.04 % sh run.sh -a 16 -s 100000 -r 1 > Y.05
The additional -a 16 command line option informs test executable to use 16 logical processors, hence running 8 instances of the “X” tests concurrently, as those tests all are two thread tests. This technique of flooding the tested machine obviously yields better resource usage and, according to our experience, favours outcome variability.
The following table summarises the results:
| Y.01 | Y.02 | Y.03 | Y.04 | Y.05 | |
| X000 | 2.3k/800k | 602/800k | 465/800k | 551/800k | 297/800k |
| X001 | 2.9k/800k | 632/800k | 774/800k | 667/800k | 315/800k |
| X002 | 633/800k | 55/800k | 5/800k | 7/800k | 0/800k |
| X003 | 1.2k/800k | 182/800k | 152/800k | 390/800k | 57/800k |
| X004 | 2.4k/800k | 974/800k | 1.5k/800k | 2.4k/800k | 1.6k/800k |
| X005 | 239/800k | 21/800k | 8/800k | 0/800k | 1/800k |
| X006 | 912/800k | 129/800k | 102/800k | 143/800k | 14/800k |
Again, we observe all targeted relaxed outcomes. In fact, x86 relaxations are relatively easy to observe on our 16 logical core machine.
Another test statistic of interest is efficiency, that is the number of targeted outcomes observed per second:
| Y.01 | Y.02 | Y.03 | Y.04 | Y.05 | |
| X000 | 285 | 2.2k | 6.6k | 9.2k | 4.2k |
| X001 | 366 | 2.4k | 13k | 11k | 5.2k |
| X002 | 78 | 212 | 71 | 140 | |
| X003 | 150 | 650 | 2.5k | 7.8k | 950 |
| X004 | 288 | 3.7k | 25k | 59k | 32k |
| X005 | 28 | 72 | 114 | 17 | |
| X006 | 118 | 461 | 1.7k | 2.9k | 280 |
As we can see, although the setting -s 10 -r 10000 yields the most relaxed outcomes, it may not be considered as the most efficient. Moreover, we see that tests X002 and X005 look more challenging than others.
Finally, it may be interesting to classify the “X” tests:
% mcycles7 @all | classify7 -arch X86 R X003 -> R+po+rfi-po : PodWW Coe Rfi PodRR Fre X006 -> R : PodWW Coe PodWR Fre SB X000 -> SB+rfi-pos : Rfi PodRR Fre Rfi PodRR Fre X001 -> SB+rfi-po+po : Rfi PodRR Fre PodWR Fre X002 -> SB+mfence+rfi-po : MFencedWR Fre Rfi PodRR Fre X004 -> SB : PodWR Fre PodWR Fre X005 -> SB+mfence+po : MFencedWR Fre PodWR Fre
One sees that two thread non-SC tests for x86 are basically of two kinds.
In this section we describe how to produce the C sources of tests on a machine, while running the tests on another. We also describe a sophisticated affinity experiment.
We assume a directory tst-ppc (archive), that contains a series of litmus tests and an index file @all. Those tests where produced by the diycross7 tool. They illustrate variations of the classical IRIW test.
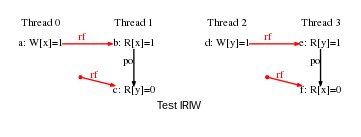
More specifically, the IRIW variations are produced as follows (see also Sec. 10):
% mkdir tst-ppc % diycross7 -name IRIW -o tst-ppc Rfe PodRR,DpAddrdR,LwSyncdRR,EieiodRR,SyncdRR Fre Rfe PodRR,DpAddrdR,LwSyncdRR,EieiodRR,SyncdRR Fre Generator produced 15 tests
We target a Power7 machine described by the configuration file power7.cfg:
#Machine/OS specification os = linux word = w64 smt = 4 smt_mode = seq #Test parameters size_of_test = 1000 number_of_run = 10 avail = 0 memory = direct stride = 1 affinity = incr0
One may notice the SMT (Simultaneaous Multi-Threading) specification:
4-ways SMT (smt=4), logical processors pertaining
to the same core being numbered in sequence (smt_mode = seq) —
that is, logical processors from the first core are 0, 1 ,2 and 3;
logical processors from the second core are 4, 5 ,6 and 7; etc.
The SMT specification is necessary to enable
custom affinity mode
(see Sec. 2.2.4).
One may also notice the specification of 0 available logical processors
(avail=0).
As affinity support is enabled (affinity=incr0),
test executables will find themselves
the number of logical processors available on the target machine.
We compile tests to C-sources packed in archive a.tar and upload the archive to the target power7 machine as follows:
% litmus7 -mach power7 -o a.tar tst-ppc/@all % scp a.tar power7:
Then, on power7 we unpack the archive and produce executable tests as follows:
power7% tar xmf a.tar power7% make -j 8 gcc -D_GNU_SOURCE -Wall -std=gnu99 -O -m64 -pthread -O2 -c affinity.c gcc -D_GNU_SOURCE -Wall -std=gnu99 -O -m64 -pthread -O2 -c outs.c gcc -D_GNU_SOURCE -Wall -std=gnu99 -O -m64 -pthread -S IRIW+eieios.c ...
As a starter, we can check the effect of available logical processor detection and custom affinity control (option +ca) by passing the command line option -v to one test executable, for instance IRIW.exe:
power7% ./IRIW.exe -v +ca
./IRIW.exe -v +ca
IRIW: n=8, r=10, s=1000, st=1, +ca, p='0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31'
thread allocation:
[23,22,3,2] {5,5,0,0}
[7,6,15,14] {1,1,3,3}
[11,10,5,4] {2,2,1,1}
[21,20,27,26] {5,5,6,6}
[9,8,25,24] {2,2,6,6}
[31,30,13,12] {7,7,3,3}
[19,18,29,28] {4,4,7,7}
[1,0,17,16] {0,0,4,4}
...
We see that our machine power7 features 32 logical processors
numbered from 0 to 31
(cf p=... above) and will thus run n=8 concurrent
instances of the 4 thread IRIW test.
Additionally allocation of threads to logical processors is shown:
here, the four threads of the test are partitioned into two groups, which are
scheduled to run on different cores. For example, threads 0 and 1 of
the first instance of the test will run on logical processors 23 and 22
(core 5); while threads 2 and 3 will run on logical
processors 3 and 2 (core 0).
Our experiment consists in running all tests with affinity increment (see Sec. 2.2.1) being from 0 and then 1 to 8 (option -i i), as well as in random and custom affinity mode (options +ra and +ca):
power7% for i in $(seq 0 8) > do > sh run.sh -i $i > Z.0$i > done power7% sh run.sh +ra > Z.0R power7% sh run.sh +ca > Z.0C
The following table summarises the results, with X meaning that the targeted relaxed outcome is observed:
| Z.00 | Z.01 | Z.02 | Z.03 | Z.04 | Z.05 | Z.06 | Z.07 | Z.08 | Z.0C | Z.0R | |
| IRIW | X | X | X | X | X | X | X | X | X | ||
| IRIW+addr+po | X | X | X | X | X | ||||||
| IRIW+addrs | X | X | X | ||||||||
| IRIW+eieio+addr | X | X | X | ||||||||
| IRIW+eieio+po | X | X | X | ||||||||
| IRIW+eieios | X | X | X | X | |||||||
| IRIW+lwsync+addr | X | X | X | ||||||||
| IRIW+lwsync+eieio | X | X | X | ||||||||
| IRIW+lwsync+po | X | X | X | X | X | ||||||
| IRIW+lwsyncs | X | X | |||||||||
| IRIW+sync+addr | X | X | |||||||||
| IRIW+sync+eieio | X | X | |||||||||
| IRIW+sync+lwsync | X | X | |||||||||
| IRIW+sync+po | X | X | X | X | X | X | |||||
| IRIW+syncs |
On sees that all possible relaxed outcomes shows up with proper affinity control. More precisely, setting the affinity increment to 2 or resorting to custom affinity result in the same effect: the first two threads of the test run on one core, while the last two threads of the test run on a different core. As demonstrated by the experiment, this allocation of test threads to cores suffices to favour relaxed outcomes for all tests except for IRIW+syncs, where the sync fences forbid them.
Together litmus7 options -gcc and -linkopt permit using a C cross compiler. For instance, assume that litmus7 runs on machine A and that crossgcc, a cross compiler for machine C, is available on machine B. Then, the following sequence of commands can be used to test machine C:
A% litmus7 -gcc crossgcc -linkopt -static -o C-files.tar ... A% scp C-files.tar B: B% tar xf C-files.tar B% make B% tar cf /tmp/C-compiled.tar . B% scp /tmp/C-compiled.tar C: C% tar xf C-compiled.tar C% sh run.sh
Alternatively, using option -crossrun C,
one can avoid copying the archive C-compiled.tar to machine C:
A% litmus7 -crossrun C -gcc crossgcc -linkopt -static -o C-files.tar ... A% scp C-files.tar B: B% tar xf C-files.tar B% make B% sh run.sh
More specifically, option -crossrun C instructs the run.sh script to upload executables individually to machine C, just before running them. Notice that executables are removed from C once run.
We illustrate the crossrun feature by testing LB variations on an ARM-based Tegra3 (4 cores) tablet. Test LB (load-buffering) exercises the following “causality” loop:
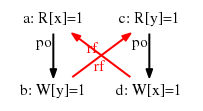
That is, thread 0 reads the values stored to location x by thread 1, thread 1 reads the values stored to location y by thread 0, and both threads read “before” they write.
We shall consider tests with varying interpretations of “before”: the write may simply follow the read in program order (po in test names), may depend on the read (data and addr), or they may be some fence in-betweeen (isb and dmb). We first generate tests tst-arm (archive) with diycross7:
% mkdir tst-arm % diycross7 -arch ARM -name LB -o tst-arm PodRW,DpDatadW,DpCtrldW,ISBdRW,DMBdRW Rfe PodRW,DpDatadW,DpCtrldW,ISBdRW,DMBdRW Rfe Generator produced 15 tests
We use the following, tegra3.cfg, configuration file:
#Tegra 3 size_of_test = 5k number_of_run = 200 avail = 4 memory = direct #Cross compilation gcc = arm-linux-gnueabi-gcc ccopts = -march=armv7-a -O2 linkopt = -static
Notice the “cross-compilation” section: the name of the gcc cross-compiler is arm-linux-gnueabi-gcc, while the adequate version of the target ARM variant and static linking are specified.
We compile the tests from litmus source files to C source files in directory TST as follows:
% mkdir TST % litmus7 -mach tegra3 -crossrun app_81@wifi-auth-188153:2222 tst-arm/@all -o TST
The extra option -crossrun app_81@wifi-auth-188153:2222 specifies the address to log onto the tablet by ssh, which is connected on a local WiFi network and runs a ssh daemon that listens on port 2222.
We compile to executables and run them as as follows:
% cd TST % make arm-linux-gnueabi-gcc -Wall -std=gnu99 -march=armv7-a -O2 -pthread -O2 -c outs.c arm-linux-gnueabi-gcc -Wall -std=gnu99 -march=armv7-a -O2 -pthread -O2 -c utils.c arm-linux-gnueabi-gcc -Wall -std=gnu99 -march=armv7-a -O2 -pthread -S LB.c ... % sh run.sh > ARM-LB.log
(Complete run log.) It is important to notice that the shell script run.sh runs on the local machine, not on the remote tablet. Each test executable is copied (by using scp) to the tablet, runs there and is deleted (by using ssh), as can be seen with sh “-x” option:
% sh -x run.sh 2>&1 >ARM-LB.log | grep -e scp -e ssh + scp -P 2222 -q ./LB.exe app_81@wifi-auth-188153: + ssh -p 2222 -q -n app_81@wifi-auth-188153 ./LB.exe -q && rm ./LB.exe + scp -P 2222 -q ./LB+data+po.exe app_81@wifi-auth-188153: + ssh -p 2222 -q -n app_81@wifi-auth-188153 ./LB+data+po.exe -q && rm ./LB+data+po.exe ...
Experiment results can be extracted from the log file quite easily, by reading the “Observation” information from test output:
% grep Observation ARM-LB.log Observation LB Sometimes 1395 1998605 Observation LB+data+po Sometimes 360 1999640 Observation LB+ctrl+po Sometimes 645 1999355 Observation LB+isb+po Sometimes 1676 1998324 Observation LB+dmb+po Sometimes 18 1999982 Observation LB+datas Never 0 2000000 Observation LB+ctrl+data Never 0 2000000 Observation LB+isb+data Sometimes 654 1999346 Observation LB+dmb+data Never 0 2000000 Observation LB+ctrls Never 0 2000000 Observation LB+isb+ctrl Sometimes 1143 1998857 Observation LB+dmb+ctrl Never 0 2000000 Observation LB+isbs Sometimes 2169 1997831 Observation LB+dmb+isb Sometimes 178 1999822 Observation LB+dmbs Never 0 2000000
What is observed (Sometimes) or not (Never) is the occurence of the non-SC behaviour of tests. All tests have the same structure and the observation of the non-SC behaviour can be interpreted as some read not being “before” the write by the same thread. This situation occurs for plain program order (plain test LB and po variations) and for the isb fence.
The following graph summarises the observations and illustrates that data dependencies, control dependencies and the dmb barrier apparently suffice to restore SC in the case of the LB family.
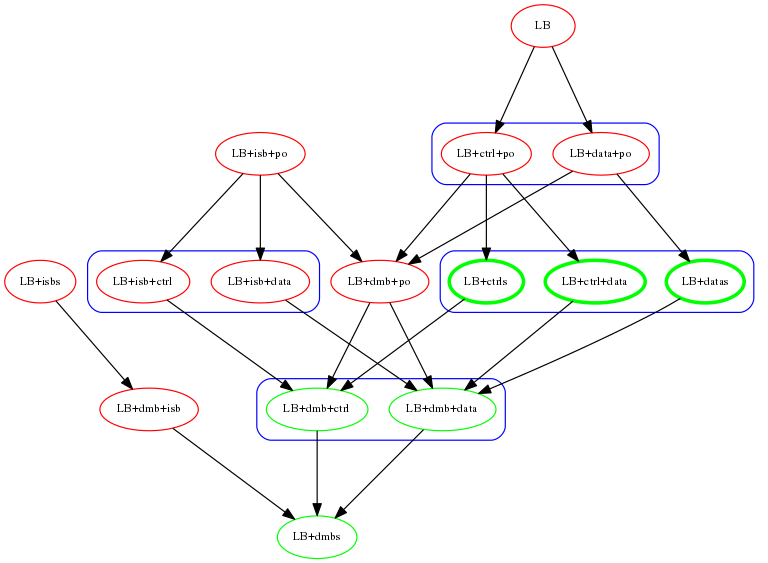
In the graph above, a red node means an observation of the non-SC behaviour.